CrossQ
Contents
CrossQ#
제목: Cross\(Q\): Batch Normalization in Deep Reinforcement Learning for Greater Sample Efficiency and Simplicity
저자: Bhatt, Aditya, Daniel Palenicek, Boris Belousov, and Max Argus, Cornell University
연도: 2024년
학술대회: ICLR
키워드: Off-policy, Sample efficiency
오늘은 얼마 전에 accpetance decision이 나온 2024 ICLR 논문 중 spotlight로 지정된 CrossQ 알고리즘에 대해 리뷰해볼 것이다. 아니 2024년 ICLR 논문이라면서 왜 arXiv identifier는 19년도야? 그렇다. 이 논문의 아주 초기 아이디어는 2019년에 나온 것이 맞다. 초기 아이디어를 다듬고 또 다듬고 또 다듬어서 결국 이번에 2024 ICLR에 승인된 것이다. 아이디어를 구현해서 빠르게 결과가 나지 않으면 안 된다고 단정 짓고 다른 아이디어로 넘어가는 나 자신을 반성한다. 결과가 안 좋으면 시간을 들여서 좋게 만들면 되는 것인데 말이다.
아무튼 이 논문은 다소 충격적이다. DQN 등장 이후로 많은 off-policy value-based 방법론들은 target critic network을 필수적으로 사용했다. 실제로 SAC에서 target network를 삭제하면 학습 아예 안 되거나 발산한다고 한다. 하지만, 이 논문에서는 target network를 삭제한다. 그 대신 학습 안정성을 확보하게 위하여 critic network에 batch normalization을 추가한다.
아니 굳이 target network 지우지 않고 batch normalization만 추가해도 성능 오르는거 아니야?라고 생각할 수 있다. 학습 안정성에 도움을 준다는 batch normalization은 유독 강화학습 분야에서는 적용 사례가 별로 없다. 그 이유는 강화학습 특성상 입력 데이터인 state-action pair \((s, a)\)의 분포가 계속 달라지기도 하고, 학습은 state-action pair \((s, a)\)에 대해 진행되는데, next value를 계산할 때는 다음 state-action pair인 \((s', a'_{\pi})\)이 입력되기 때문이다. 즉, \((s, a)\)에 대해 계산된 statistics을 \((s', a'_{\pi})\)에 적용하니 오히려 악영향을 끼치는 것이다.
아무튼 CrossQ의 요약은 다음 세 줄이다.
SAC에서 target network 삭제하기
그 대신 critic network에 batch normalization 추가하기
위 2가지로 충분하지만, 성능을 조금 더 끌어올리기 위하여 wider한 네트워크 사용하기
첫 번째와 두 번째 항목이 이 논문의 main contribution이고, 세 번째는 이 논문의 contribution은 아니다. 위 세 가지 수정 사항만으로 SAC과 비교하여 성능이 압도적으로 개선되었다. 얼마나 성능이 향상되었냐면, CrossQ의 성능은 SAC 계열 SOTA 알고리즘인 REDQ와 DroQ과 동등하거나 그 이상이다.
참고로 REDQ는 10개의 critic network를 앙상블하는 알고리즘이고, DroQ는 critic network을 개수를 늘리는 대신 dropout을 통해 앙상블을 하는 알고리즘이다. 그리고 두 알고리즘 모두 update-to-data (UTD) ratio를 20까지 올린 알고리즘이다. 즉, sample efficiency를 위하여 1 environment step마다 네트워크를 20번 학습시킨다는 뜻이다. 즉, REDQ와 DroQ는 critic 앙상블을 통하여 1보다 큰 UTD ratio 사용을 가능하게 만들었고, sample efficiency를 확보하여 SAC보다 더 빠르게 더 높은 성능을 도달한 알고리즘들이다. 하지만 CrossQ는 UTD=1로 설정했는데, REDQ와 DroQ만큼 빠르게 동등하거나 높은 성능을 기록하였다.
Experiment#
Gym의 MuJoCo benchmark를 사용했다. image observation은 아니고, true vector state를 사용한다. Image observation에 대한 이야기가 없어서 아쉬웠다. 아래는 학습 곡선이다. 보통 Gym의 MuJoCo 벤치마킹 1백만번 정도 학습시켰는데, \(x\)축을 보면 알겠지만 30만 번에 대한 학습 곡선이다. REDQ, DroQ, CrossQ 모두 환경과의 적은 상호작용 횟수만으로도 높은 성능을 기록한다.
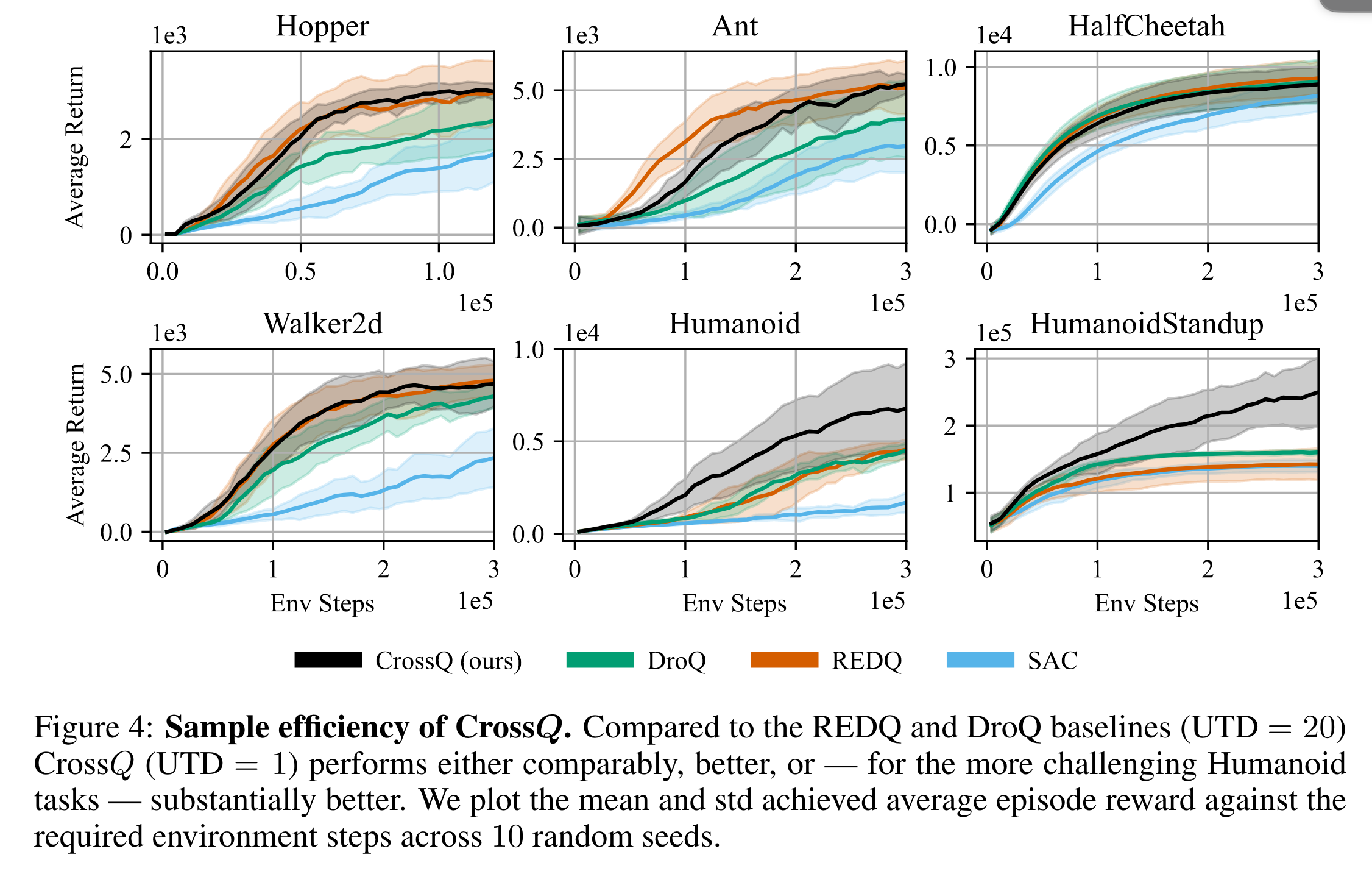
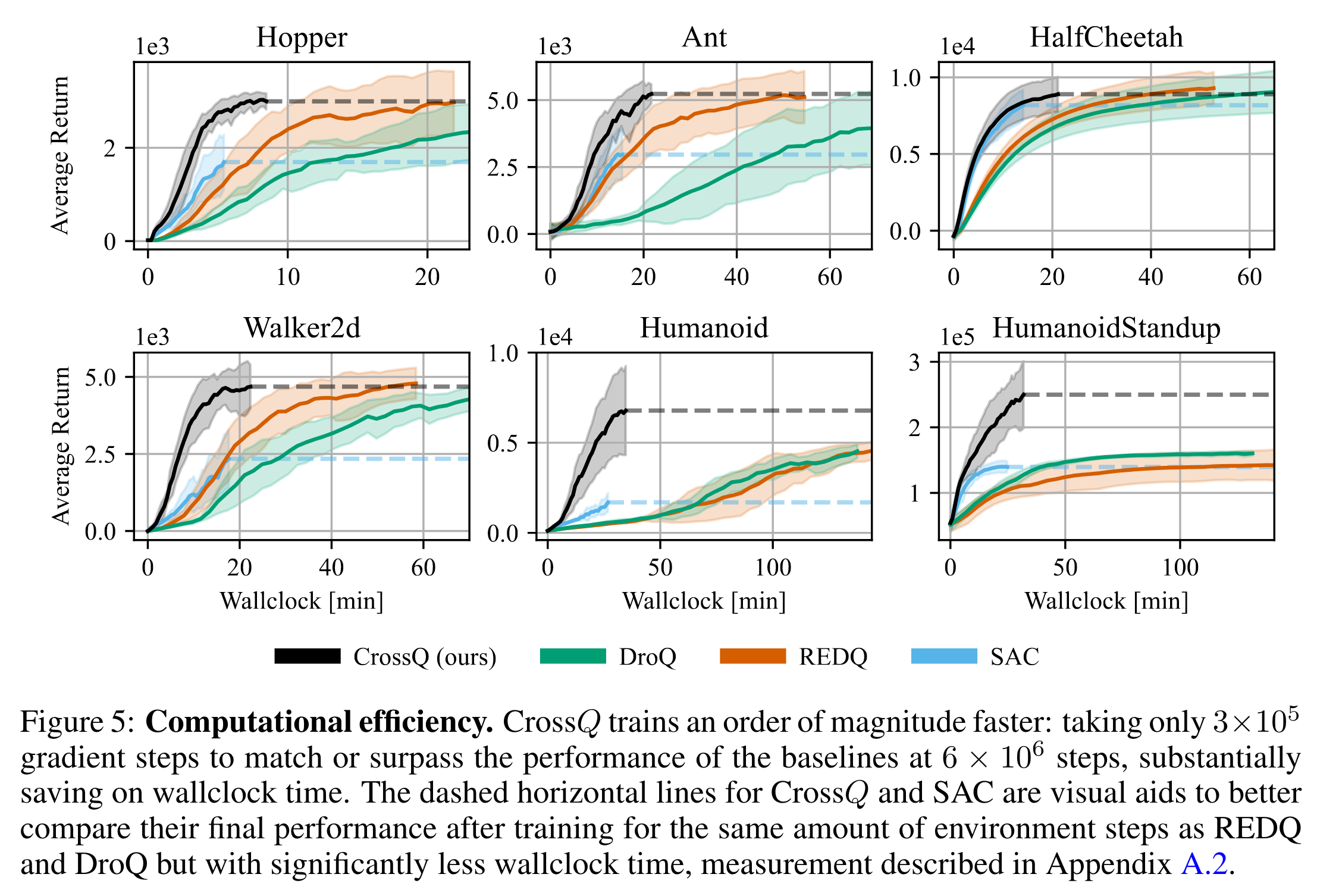
아래는 학습 경과 시간에 따른 성능 그래프이다. REDQ, DroQ는 사실 환경과의 상호작용 횟수만 적을 뿐 앙상블 및 UTD=20을 사용하기 때문에 학습에 소요되는 시간은 훨씬 더 길다. 하지만, CrossQ는 SAC와 비슷한 학습 시간만으로도 높은 성능을 기록할 수 있다.
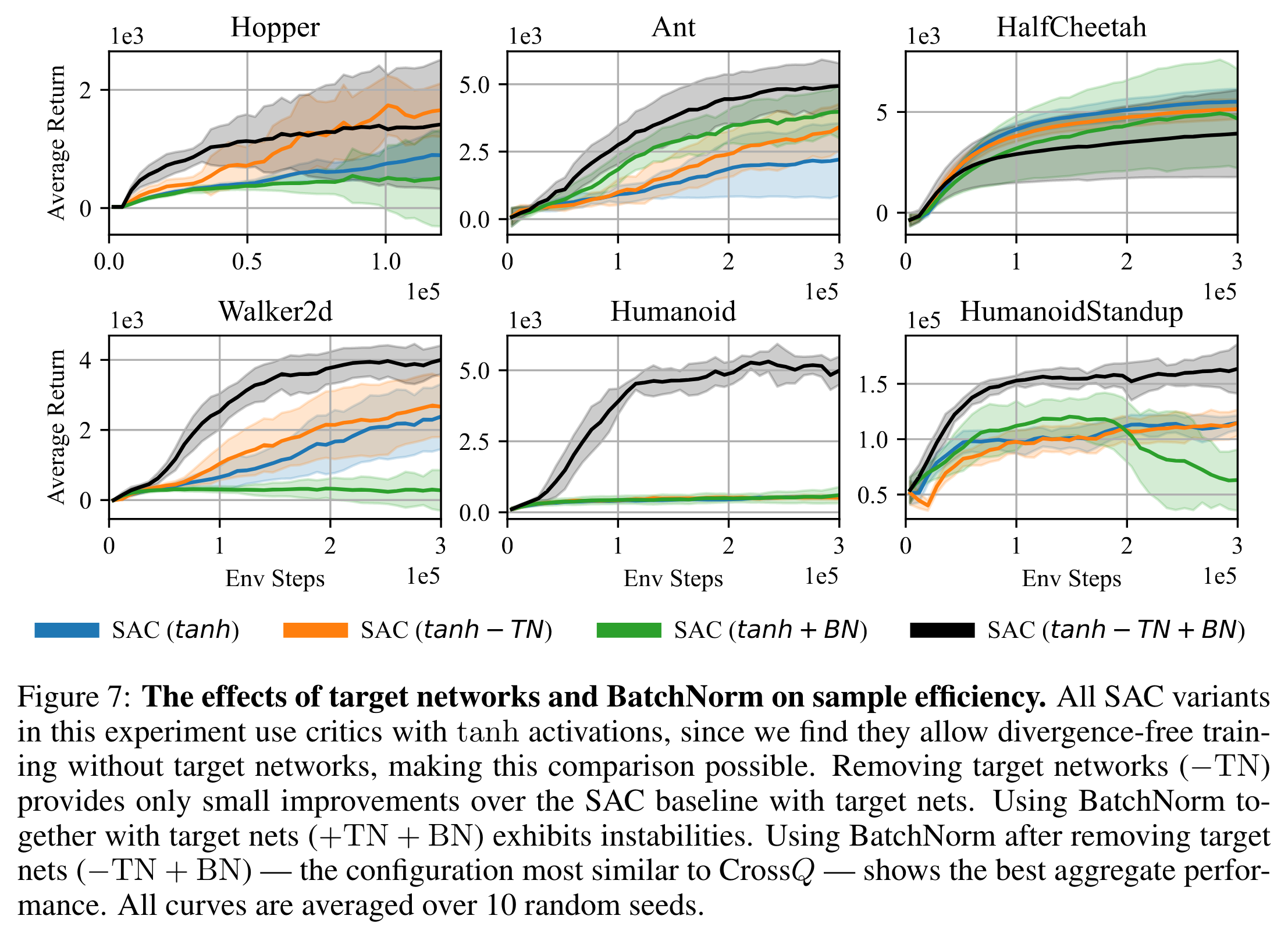
아래는 ablation study이다. SAC에서 target network를 삭제하면 아예 학습이 안 되게 된다. 그러면 ablation study을 하기 어려울 것이다. 따라서 이 실험에서는 critic의 activation 함수를 ReLU 대신 bounded activation 함수인 tanh를 사용하였다. Bounded activation 함수를 사용하게 되면 target network를 삭제해도 네트워크가 발산하는 현상이 줄어든다고 한다. \(-TN\)이 target network를 삭제한 것. \(BN\)이 critic network에 batch normalization을 추가한 것이다. Target network를 삭제해주고 batch normalization을 해줘야만 성능이 대폭 향상하게 된다 (HalfCheetah는 함정..).
마치며#
다음 생각이 든다.
Image observation에서도 잘 작동할까?
DQN 계열에서도 마찬가지 결과를 얻을 수 있을까?
코드가 빨리 공개되었으면 좋겠다.
이상 글을 마치도록 하겠다.