PLASTIC
Contents
PLASTIC#
제목: PLASTIC: Improving Input and Label Plasticity for Sample Efficient Reinforcement Learning
저자: Lee, Hojoon, Hanseul Cho, Hyunseung Kim, Daehoon Gwak, Joonkee Kim, Jaegul Choo, Se-Young Yun, and Chulhee Yun, KAIST
연도: 2023년
학술대회: NeurIPS
키워드: Off-policy, overfitting, plasticity
NeurIPS 2023에 accept된 논문들 중 읽을 만한 논문들 찾다가 발견한 한국인 저자의 논문. 주제도 off-policy RL 알고리즘들의 overfitting에 관한 것이고, 이론보다는 empirical한 실험 위주의 논문이라서 흥미롭게 읽었다. 논문의 내용과 관련 없지만, 특히 인상 깊었던 것은 저자분께서 최신 논문을 엄청나게 많이 읽으신다는 것이었다. 예를 들어, 2023년 2~3월쯤 arXiv에 올라온 (추후 ICML에 승인된) 논문들을 읽으시고 5월 중순 마감인 Neurips 2023에 제출할 때 해당 논문들을 참고문헌으로 넣으셨다. 최신 동향을 파악하고 실험까지 빠르게 진행하여 논문을 쓴다는 점을 본받아야 할 것 같다.
Overview#
심층강화학습에서 off-policy 알고리즘들은 replay buffer를 사용한다. Replay buffer를 사용함으로써 off-policy RL은 다음 세 가지 특징을 갖게 된다.
학습이 진행될 수록 buffer 안의 데이터가 많아진다.
학습이 진행될 수록 buffer 안의 데이터의 분포가 바뀐다.
매 environment step마다 여러번 네트워크를 훈련시킬 수 있다.
1, 2번을 반대로 생각하면 학습 초기 replay buffer 안에 안 그래도 적은 데이터가 있는데 걔네들의 품질까지 안 좋다는 것을 의미한다. 이런 안 좋은 replay buffer에서 데이터를 랜덤 샘플링하여 학습을 하기 때문에 네트워크들이 학습 초기의 early transitions에 과적합이 될 수 있고, 한 번 과적합에 빠지면 알고리즘의 성능이 향상되지 않고 정착되는 현상이 발생할 수 있다. 논문에서는 이런 현상을 loss of plasticity 이라고 부른다. Plasticity는 가소성이란 뜻을 갖고 있고, 최근 continual learning에서 많이 등장하는 단어이다. 네트워크가 이전에 학습한 데이터들을 적당히 잊고 새롭게 들어오는 데이터를 학습할 수 있어야 하는데, 이전 데이터를 잊지 못하고 과적합되었으니 알고리즘이 plasticity가 부족한 문제, 즉 loss of plasticity 문제를 겪고 있는 것이다. 논문에서는 plasticity를 크게 두 가지로 분류한다.
데이터 분포의 변화에 적응할 수 있는 능력을 input plasticity라고 부르고,
입력 데이터와 레이블 (return 또는 Q값) 사이의 관계 변화에 적응할 수 있는 능력을 label plasticity라고 부른다.
논문에서는 다음 네 가지 최신 기법을 사용하여 off-policy 알고리즘의 loss of plasticity를 완화시켰다.
Layer normalization (LN)
SAM (sharpness-aware minimiazation) optimizer
Concanated ReLU (CReLU)
Reset
LN은 loss landscape를 보다 더 smooth하게 만드는 효과가 있고, SAM은 네트워크 파라미터를 loss landscape에서 smooth한 영역으로 업데이트하는 효과가 있어서 네트워크의 일반화 성능 향상에 기여한다. 따라서 LN과 SAM은 일반화 성능을 향상시켜 데이터 분포 변화에도 대응할 수 있는 input plasticity를 향상시킨다. 한편, 딥러닝 네트워크들은 학습이 진행될 수록 active units (activation값이 0이 아닌)의 개수가 줄어들어 사실상 업데이트가 이뤄지는 파라미터가 줄어드는 문제를 갖고 있다. 이 현상을 ReLU와 -ReLU를 concanate하여 0이 아닌 activte units을 늘리는 CReLU와 네트워크 파라미터의 일부를 주기적으로 초기화시키는 reset을 사용하여 완화시켰다. 파라미터 업데이트가 지속적으로 잘 일어나니 입력과 레이블 사이의 관계가 변화해도 거기에 맞게 업데이트가 잘 일어날 것이다. 따라서 CReLU와 reset은 label plasticity를 향상시키는 효과가 있다.
Empirical evidence#
위에서 언급한 네 가지 기법이 input 및 label plasticity에 효과가 있다는 것을 보이기 위해 저자는 CIFAR10 데이터셋을 사용하여 강화학습과 비슷한 학습 상황에서 분류 네트워크를 학습시키고 성능을 확인했다. Input plasticity에 대한 실험으로 학습이 진행될 수록 점점 더 데이터가 추가되는 실험을 설계하였고, Label plasticity에 대한 실험으로 주기적으로 할당된 레이블을 바꾸는 실험을 진행하였다. 베이스라인 모델은 DQN에서 많이 사용되는 구조이며 3개의 convolutional layers와 3개의 fully-connected layer를 갖는다. 자세한 실험 환경은 논문을 참고하면 좋을 것이다.
아래 그림의 왼쪽 패널에서 LN과 SAM이 input plasticity 실험에서 base 모델보다 성능을 향상시켰다. 한편, CReLU와 reset은 label plasticity 실험에서 base 모델보다 높은 성능을 보였다.
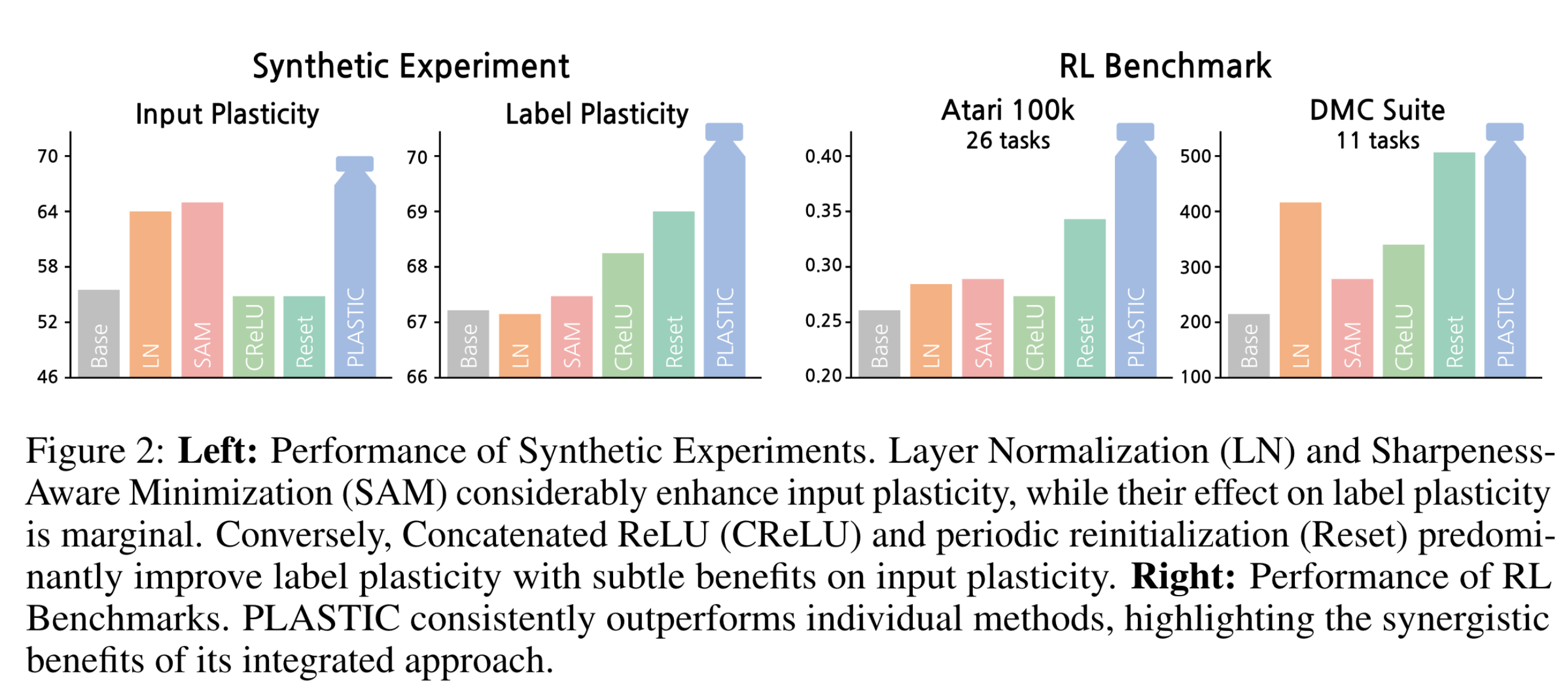
Experiment#
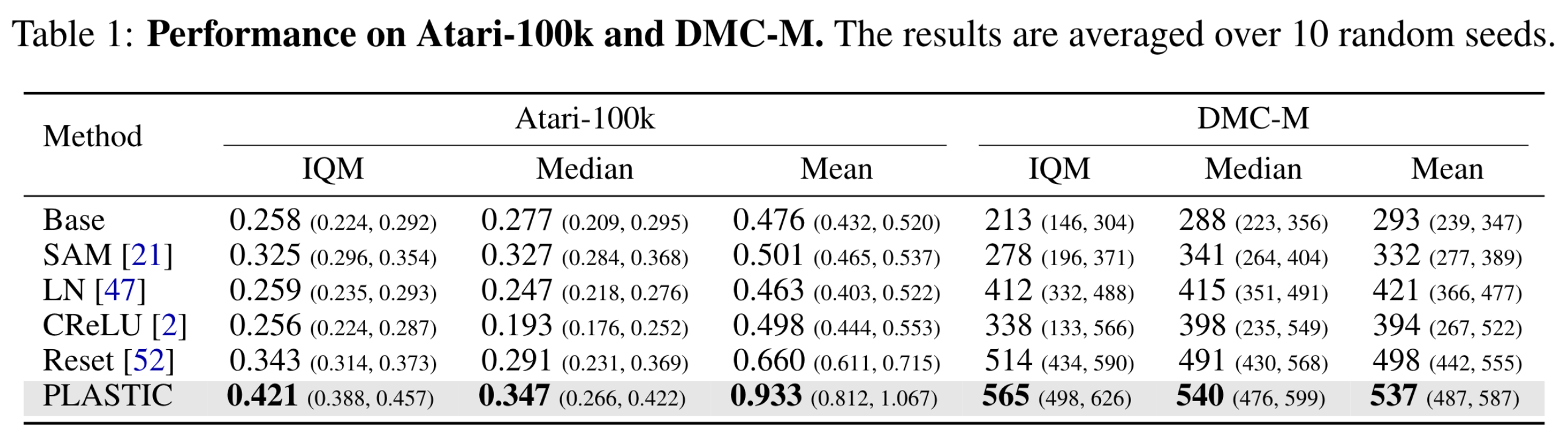
이 논문에서는 Rainbow + DrQ와 SAC + DrQ를 베이스라인 모델로 설정하고, 여기에 위에서 설명한 네 가지 기법들을 적용하여 Atari와 DMC-medium 벤치마킹 환경에서의 성능을 비교하였다. 성능이 엄청나게 향상되는 것을 확인할 수 있다. 논문에 아래 실험 외에도 다양한 실험들이 있으니 참고하면 좋을 것이다.
실제로 LN과 SAM을 통해 네트워크 파라미터가 더 smooth한 loss landscape으로 수렴한 것을 보이기 위하여 파라미터에 대한 손실함수의 Hessian matrix의 maximum eigenvalue를 측정하였다. 작을 수록 더 smooth한 영역임을 의미한다. 그리고 fully-connected layers의 active units의 비율도 측정하여 CReLU와 Reset의 효능도 검증하였다.
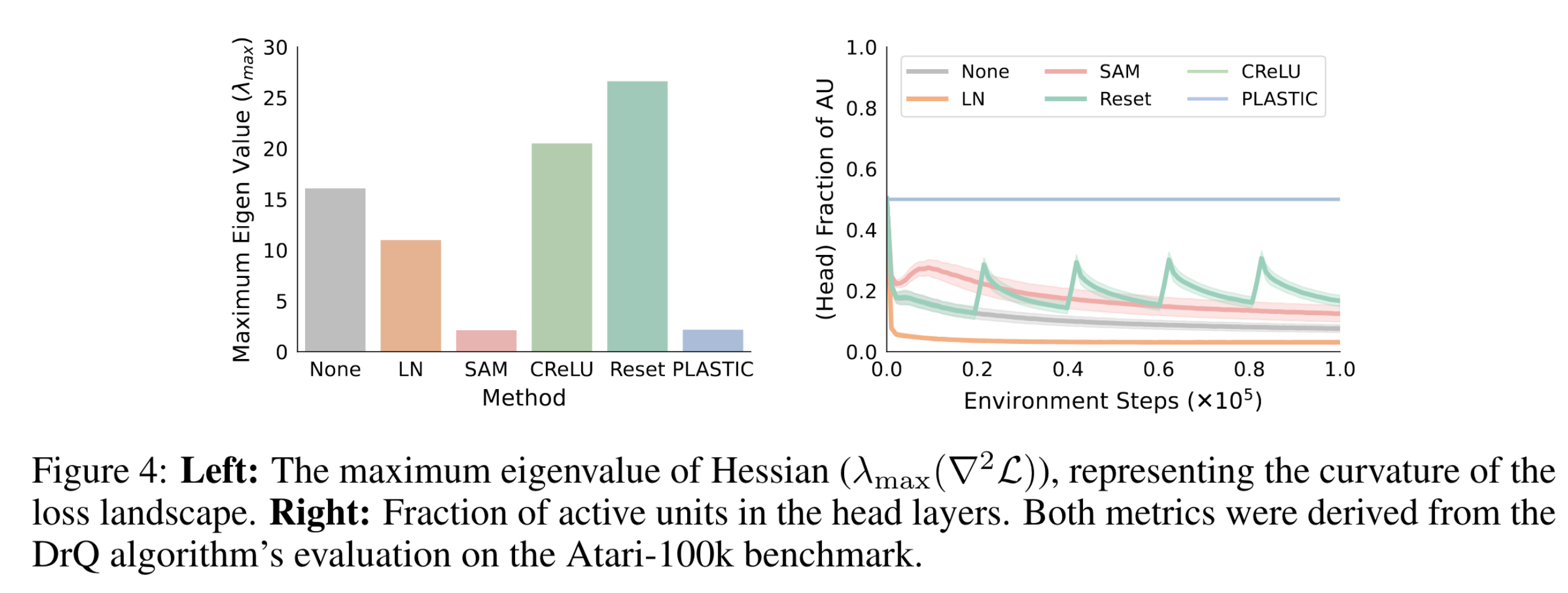
논문에는 위 실험 외에도 다양한 ablation study가 있으니 궁금하신 분들께서는 논문을 참고하시면 좋을 것 같다.