Primacy bias and Reset
Contents
Primacy bias and Reset#
제목: The Primacy Bias in Deep Reinforcement Learning
저자: Nikishin, Evgenii, Max Schwarzer, Pierluca D’Oro, Pierre-Luc Bacon, and Aaron Courville, Mila
연도: 2022년
학술대회: ICML
키워드: Off-policy, overfitting, plasticity
바로 직전에 읽은 PLASTIC 논문에서는 off-policy 알고리즘이 early experiences에 과적합되는 문제를 해결했었다. 하지만 아쉽게도 off-policy 알고리즘이 진짜 과적합 문제를 겪고 있는지에 대한 empirical evidence가 논문에 따로 없었고, 대신 지금 리뷰하고 있는 이 논문을 참고문헌으로 인용하고 있었다. 이 논문은 PLASTIC 알고리즘의 한 구성 요소인 reset 알고리즘을 제안한 논문이며, off-policy 알고리즘이 early experiences에 과적합되면 추후 좋은 데이터가 버퍼에 들어와도 성능 향상이 이뤄지지 않는다는 것을 실험을 통해 보였다.
Overview#
Off-policy 알고리즘이 학습 초기 데이터에 과적합되는 현상을 이 논문에서는 primacy bias 라고 부른다. 학습 초기에 발생한 primacy bias가 학습 과정 전체에 악영향을 끼칠 수 있다고 한다. 논문에서는 크게 다음 두 가지를 주장하고 있다.
Off-policy 알고리즘 내 네트워크들이 초기 데이터에 과적합되면 이후의 학습 과정 전체에 악영향을 끼칠 수 있다.
이후 학습 과정에 악영향을 끼치는 이유는 replay buffer 안에 나쁜 데이터가 있기 때문이 아니라, 네트워크들이 과적합됐기 때문이다.
직관적으로는 replay buffer 안에 나쁜 데이터들이 있기 때문에 알고리즘의 성능이 저하되거나 정체될 것으로 생각된다. 하지만 이 논문에서는 replay buffer 안에 나쁜 데이터들이 있어도 네트워크들은 이 안에서 좋은 정보를 학습해낼 수 있다는 것을 실험으로 보였다. 이 두 가지 주장을 바탕으로 replay buffer를 초기화하는 과정 없이 학습 과정 중 주기적으로 네트워크의 일부 파라미터들을 랜덤 초기화하는 reset 알고리즘을 제안한다.
Empirical evidence#
학습 초기 데이터에 네트워크들이 과적합될 경우 이후에 있는 모든 학습 과정 동안 알고리즘의 성능이 정체될 수 있다는 것을 실험적으로 보였다.
Deepmind Control suite (DMC)의 quadruped-run 환경에 Soft Actor-Critic (SAC) 알고리즘을 학습시킬 때,
처음 수집한 100개의 데이터를 사용하여 100,000번 네트워크를 학습시켜서 primacy bias를 발생시킨다 (좀 과하게 많이 학습시키는 것 같다).
이후 일반적인 SAC 알고리즘 학습 과정을 진행한다.
아래 그림 중 왼쪽에 있는 Figure 1이 실험에 대한 결과이다.
주황색 선은 그냥 일반적으로 SAC를 학습시킨 결과이고, 파란색 선은 primacy bias가 발생한 SAC이다.
첫 100개의 데이터에 과적합된 알고리즘은 이후 1백만번 환경과 상호작용하며 학습하는 동안 성능이 향상되지 않고 정체되어 버렸다.
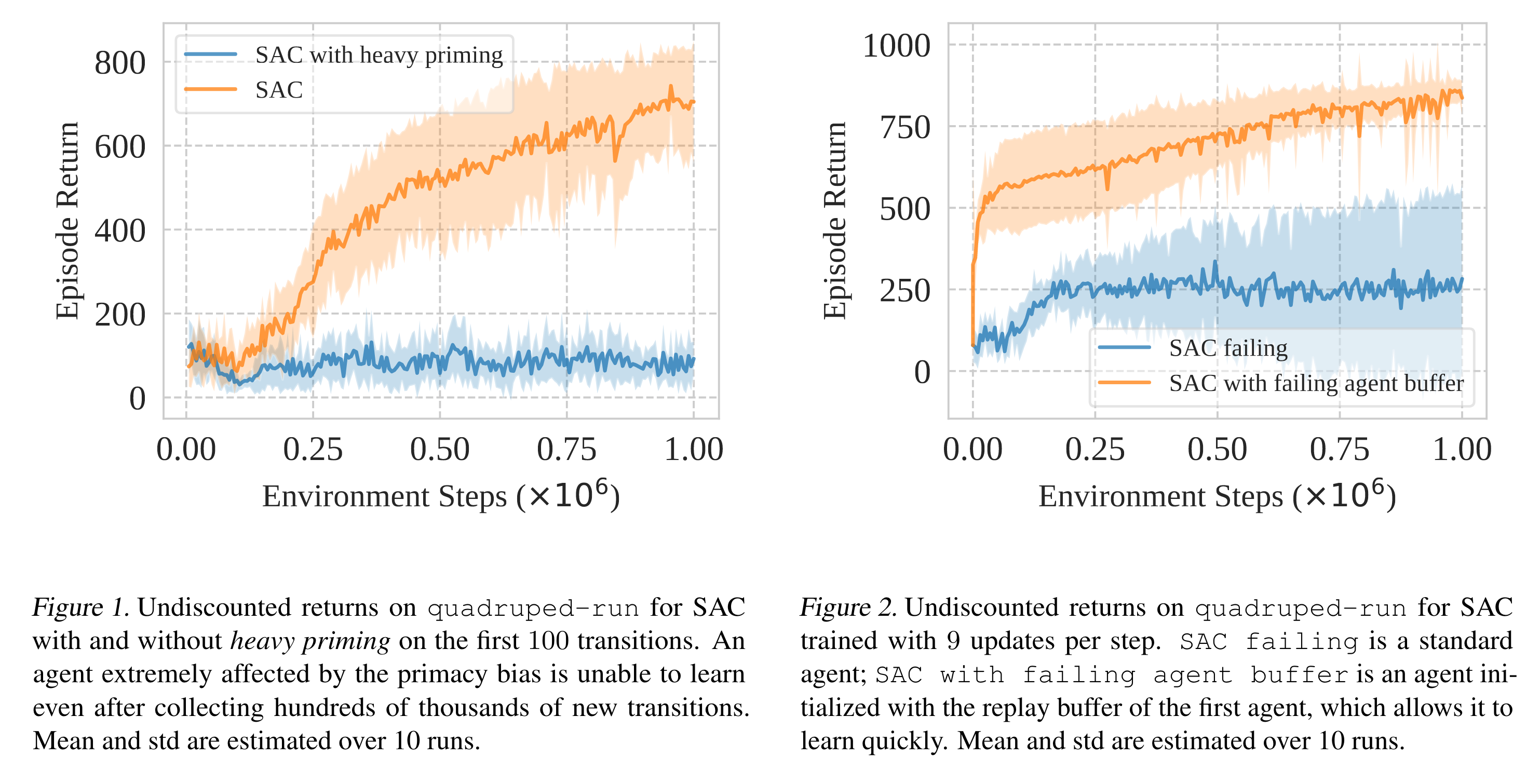
그럼 replay buffer 안에 나쁜 데이터가 그득하여 과적합된 이후에도 학습이 되지 않은 것일까? 논문의 주장은 데이터의 품질 때문에 학습이 정체된 것이 아니라 과적합된 네트워크 때문에 학습이 정체되었다는 것이다. 이를 보이기 위하여 논문에서는 먼저 한 번의 environment step마다 9번의 파라미터 업데이트를 진행하여 (replay ratio=9) primacy bias가 발생한 SAC 알고리즘을 얻었다. 이 primacy bias가 있는 SAC로 데이터를 수집하여 replay buffer를 구성하고, 이 replay buffer를 initial replay buffer로 사용하여 아예 새로운 SAC 알고리즘을 학습시켜보았다. 그 결과가 위 그림의 오른쪽에 있는 Figure 2이다. 파란색 선은 replay ratio=9로 설정하여 primacy bias가 발생한 SAC의 학습 곡선이고, 주황색 선은 primacy bias가 발생한 SAC가 수집한 replay buffer로 학습시킨 SAC의 학습 곡선이다. 이 결과를 통해 replay buffer 안에 나쁜 데이터들이 있는 것이 학습 정체의 주된 원인이 아니라, 과적합된 네트워크가 학습 정체의 주된 원인이라는 것을 알 수 있다.
Reset#
이 논문에서 재밌었던 점은 논문의 method에 해당하는 섹션이 달랑 12줄이라는 것이었다. 수식 하나 없이 말로만 메서드를 소개하는데도 잘 이해가 되었다. Reset 알고리즘은 그냥 학습 동안 네트워크의 일부 레이어 (또는 전체 레이어)의 파라미터를 주기적으로 초기화시키는 것이다.
Experiment#
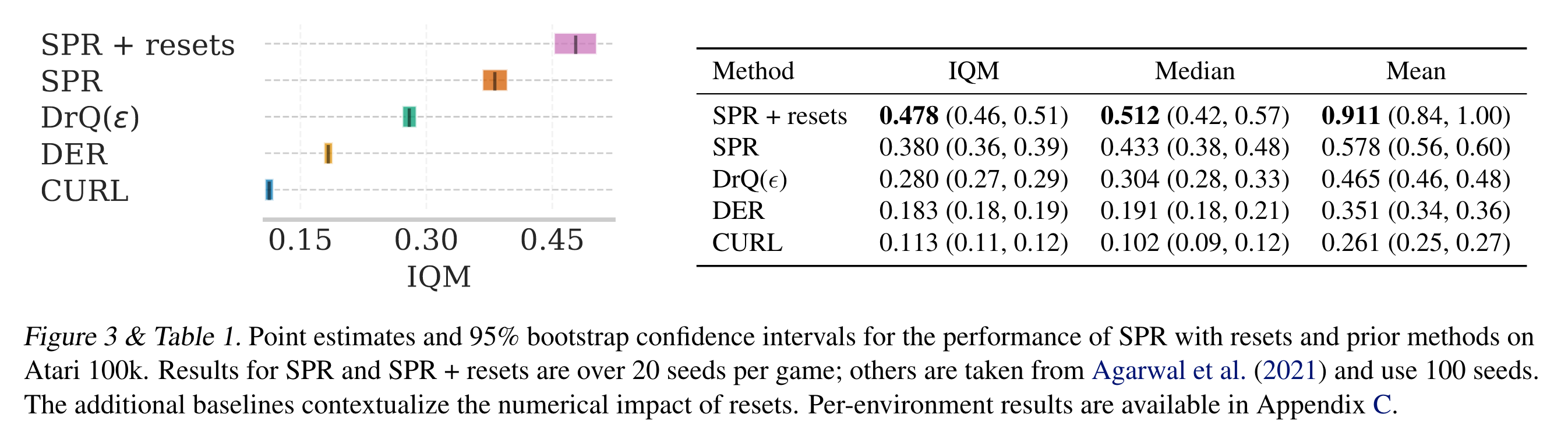
논문에서는 Atari-100K와 DMC를 벤치마킹 환경으로 사용했다. Atari-100k 실험에서는 SPR이라는 알고리즘에 reset 알고리즘을 적용하였으며 매 20,000번마다 Q네트워크의 가장 마지막 레이어의 파라미터만 초기화시켰다. DMC에서는 벡터 상태 공간일 경우 SAC 알고리즘을 사용하였으며, 매 200,000번마다 알고리즘 내 모든 네트워크들의 모든 레이어를 초기화시켰다. 벡터 상태 공간을 가질 경우 네트워크들이 3층짜리 MLP라서 그냥 다 초기화시켰다고 한다. 이미지 상태 공간일 경우 DrQ를 사용했으며 훈련 과정 동안 총 10번 네트워크의 가장 마지막 세 레이어를 초기화시켰다. Optimizer의 momentum statistics도 초기화해줬다고 하는데, 이후 실험에서 optimizer의 momentum statistics 초기화 여부는 성능에 큰 영향을 미치지 않는다고 한다.
아래는 Atari-100k에 대한 실험 결과이다. 왼쪽 그림에서 \(x\) 축이 성능인 IQM (interquantile mean) 값이다. SPR과 SPR + resets을 비교해보면 큰 성능 향상이 있는 것을 알 수 있다.
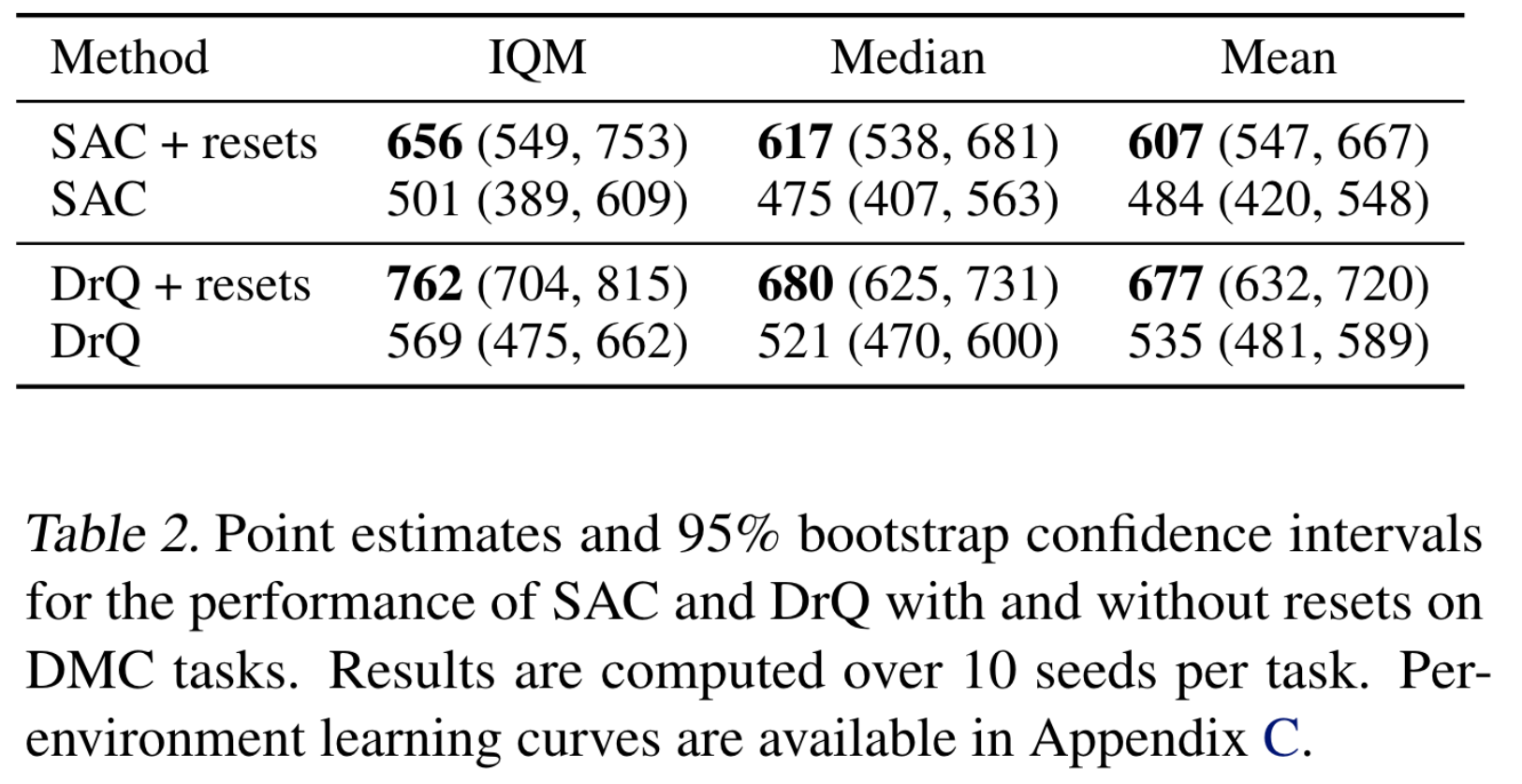
DMC에 대한 결과표이다. 참고로 Table 1과 2에서 베이스라인 알고리즘을 포함한 모든 결과는 여러 replay ratio와 \(n\)-step td target의 \(n\)값을 실험해보며 제일 좋은 결과를 선택한 것이다.
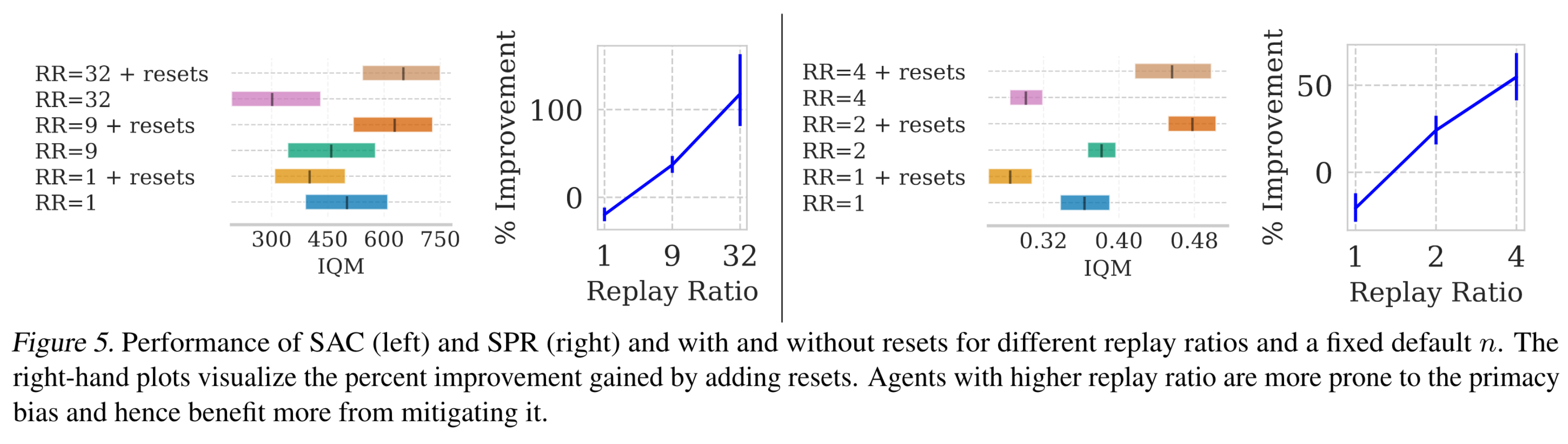
베이스라인 알고리즘들의 경우 replay ratio를 늘려도 성능이 막 올라가진 않는다. 학습 과정에서 sample efficiency로 얻는 이득보다 primacy bias로 잃는 손해가 더 많기 때문일 것이다. 하지만 reset을 적용할 경우 replay ratio를 늘리면 성능 향상을 기대할 수 있다. 이에 대한 실험 결과는 아래와 같다. 나는 아직 초짜라서 replay ratio=1인 알고리즘들만 사용하는데, 이때는 오히려 reset을 적용할 경우 성능이 떨어진다는 점이 아쉽다.
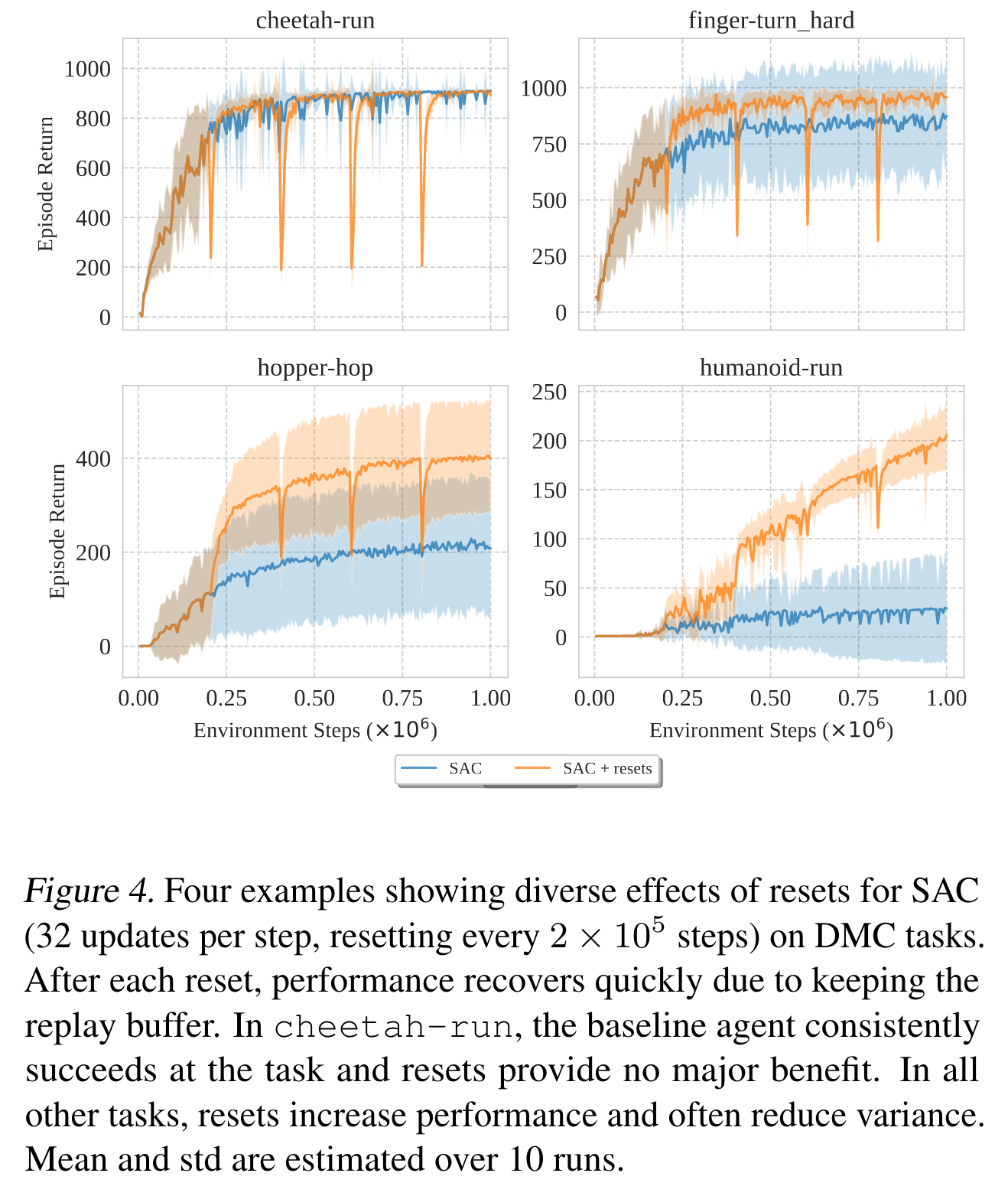
Reset 알고리즘을 적용하여 학습을 하면 다음과 같은 학습 곡선이 나온다. 뭔가 optimization 기법 중 cosine annealing을 적용했을 때와 비슷한 양상을 보인다.