
Unsupervised RL
Contents
20. Unsupervised RL#
Unsupervised RL 분야는 보상함수가 주어지지 않았을 때 다양한 행동 (behavior)을 discover 할 수 있는 에이전트를 학습하는 분야이다. 필자의 unsupervised RL에 대한 첫 인상은 그리 좋지 않았다. 보상함수가 없는 상황에서 어떤 행동들을 학습할 수 있다는 점은 신기하지만, 최종적으로 내가 원하는 행동을 하는 에이전트를 만들기 위해서는 결국 보상함수를 줘야할 것이기 때문에 굳이 보상함수 없이 에이전트를 학습시킬 필요성을 느끼지 못했기 때문이다.
하지만, CS285의 exploration part2 강의에서 나온 다음 동영상을 보고 싸악 바뀌었다.
그렇다. 영상 속 아기가 너무 귀여워서 그냥 unsupervised RL을 좋게 생각하기로 했다! 농담이고, 이 영상 속 아기가 unsupervised RL의 중요성을 잘 보여주고 있는 것 같았다. 아기에게 장난감을 갖고 노는 방법을 가르쳐 주거나 장난감을 성공적으로 갖고 놀았을 때 보상을 준 것도 아닌데, 아기는 혼자서 방 안을 이리 저리 움직이며 장난감들을 마음대로 움직여 본다. 예상컨데, 아기는 시간이 지나면서 각각의 장난감을 갖고 노는 방법을 스스로 터득하지 않을까 싶다.
강화학습에서 보상함수를 디자인하는 것이 제일 어려운만큼 보상함수 없이 사용자가 원하는 행동을 하는 에이전트를 얻을 수 있다면 그것만큼 좋은 것이 없을 것이다. 그래서 필자는 unsupervised RL 분야가 굉장히 유망하다고 생각한다. 물론, 아직까지는 unsupervised RL만으로 복잡한 task를 수행할 정도는 아니다. 주로 unsupervised RL 알고리즘으로 뉴럴 네트워크를 사전훈련시키고, 보상함수가 정의되어 있는 downstream task에서 미세조정하는 방식이 많다. 사실 좀 대충 말하면 그냥 주어진 환경의 상태공간을 보상함수 없이 잘 exploration하는 에이전트를 찾는 분야라고 할 수 있다.
20.1. Unsupervised RL 접근 방법#
Unsupervised RL 분야에는 크게 두 부류의 연구가 있다. 하나는 pure exploration이고 다른 하나는 skill discovery이다.
20.1.1. Pure exploration#
Pure exploration 방법론들은 말 그대로 훈련 동안 상태공간을 최대한 많이 탐험하는 것을 목표로 한다. 필자의 짧은 소견으로는 pure exploration 방법론은 다시 크게 2가지 접근법으로 나뉜다. 첫 번째는 curiosity-based intrinsic reward를 이용하는 접근법이고, 두 번째는 정책의 state visitation frequency의 entropy를 최대화하는 접근법이다.
20.1.1.1. Curiosity-based intrinsic reward#
먼저, 환경에서 정의해놓은 task reward (또는 extrinsic reward) 외에 특정 목적을 달성하기 위하여 강화학습 알고리즘 내부적으로 만들어서 이용하는 보상함수를 intrisic reward라고 부른다. 한편, 탐험 (exploration)의 목적은 지금까지 에이전트가 가보지 못한 새로운 상태 (novel states)에 방문하는 것이이다. 따라서 지금까지 덜 방문한 상태에 더 큰 보상을 주는 방식으로 intrinsic reward를 정의하면 에이전트가 탐험을 할 수 있도록 유도할 수 있을 것이다.
가장 단순한 방법으로는 각 상태에 방문한 횟수를 직접 세서 방문 횟수가 적은 상태에는 큰 보상을 주고, 방문을 많이 한 상태일수록 점점 더 작은 보상을 주는 방식을 생각해볼 수 있을 것이다. 예컨데, 방문 횟수의 역수를 보상으로 줄 수 있을 것이다.
where \(N(s)\)는 학습 동안 상태 \(s\)에 방문한 횟수이다 (여기서 \(\text{i}\)는 intrinsic의 \(\text{i}\)이다). 이미지 상태공간처럼 상태공간의 크기가 큰 경우 모든 상태에 대해서 방문 횟수를 모두 세는 것이 불가능하기도 하고, 몇 픽셀 차이나지 않는 거의 동일한 상태에 대해서도 방문 횟수를 따로 세는 것은 비효율적일 것이다.
이러한 방문 횟수 기반 intrinsic reward의 한계를 보완할 수 있는 방법으로 딥러닝 모델의 prediction error를 사용하는 방법이 있다. 학습 동안 많이 본 데이터에 대해서는 딥러닝 모델의 예측 성능이 높고, 적게 본 데이터에 대해서는 예측 성능이 낮은 성질을 이용하는 것이다. Prediction error를 기반으로 intrinsic reward를 정의하는 알고리즘들은 상태 (또는 추가적으로 행동)를 입력 받는 딥러닝 모델 \(f_\theta(s_t)\)를 갖고 있다. 그리고, 각 입력마다 레이블 \(y_t\)를 부여하는 규칙도 갖고 있어야 한다. 학습 동안에는 수집한 데이터들을 이용하여 \(f_\theta(s_i)\)가 \(y_i\)를 예측하도록 학습시킨다. 그리고 에이전트가 환경과 상호작용하는 동안 마주한 상태 \(s_t\)에 대해서 다음과 같은 intrinsic reward를 부여한다.
만약 학습 동안 상태 \(s_t\)를 많이 방문했다면, prediction error가 작을 것이기 때문에 작은 intrinsic reward를 받을 것이고, 적게 방문했다면 prediction error가 커서 intrisic reward가 클 것이다. 따라서 적게 방문한 샹태를 더 많이 방문하도록 에이전트가 훈련될 것이다. \(y_t\)를 어떻게 정의하느냐에 따라서 알고리즘의 이름이 달라진다. 알고리즘에 따라 \(y_i\)를 스칼라로 정의하기도 하고 벡터로 정의하기도 한다. \(y_t\)를 다음 상태 \(s_{t+1}\) (또는 다음 상태의 임베딩 벡터 \(\phi(s_{t+1})\))로 정의한 알고리즘을 Intrinsic Curiosity Module (ICM) [5] 이라고 부른다. 한편, \(y_t\)를 고정된 randomly initialized 뉴럴 네트워크의 출력 값 \(y_t=g_{\bar{\psi}}(s_t)\)으로 설정한 연구를 RND [6]라고 부른다.
Prediction error를 기반으로 intrinsic reward를 줄 경우, stochastic dynamics를 갖는 환경에서 prediction error가 상태 전이의 stochasticity에 의해 발생한 것인지, 아니면 덜 학습이 되어 발생한 것인지 구분하기 어려운 문제가 있다. 이를 해결하기 위하여 prediction error 대신 여러 네트워크들의 출력값의 분산을 intrinsic reward로 정의하는 연구인 Disagreement [7]도 있다. 지금까지 설명한 세 가지 알고리즘을 간단한 navigation 환경에 적용하여 비교한 그림 Fig. 20.1을 참고하면 좋을 것 같다.
20.1.1.2. Entropy maximization#
정책 \(\pi_\theta\)의 (normalized) state visitation frequency \(d_{\pi_\theta}(s)\)의 entropy를 최대화하도록 \(\theta\)를 업데이트하는 접근법이다. \(d_{\pi_\theta}(s)\)의 엔트로피를 최대화한다는 것은 가능한 모든 상태 \(s\)에 대해서 최대한 uniform하게 확률을 부여하도록 정책을 훈련시키다는 것이다. 즉, 모든 상태에 골고루 방문하도록 정책이 훈련된다. Proto-RL [8]이 대표적인 알고리즘이다.
20.1.2. Skill discovery#
Pure exploration 알고리즘을 통해 학습시킨 정책은 알고리즘 특성 상 상태공간을 그냥 마구잡이로 돌아다니는 정책이 될 것이다. 어떤 일관성 있는 행동을 하기보다는 랜덤한 행동을 취하는 것으로 보일 것이다. 이러한 정책을 어떤 task를 해결하기 위해 사용하기는 어려울 것이다.
Skill discovery 방법론은 정책이 상태 뿐만 아니라 latent variable \(z\)도 입력 받는 것이 특징이다. 즉, 정책이 \(\pi_\theta(a|s,z)\)가 된다. Latent variable을 입력 받는 목적은 같은 상태에서라도 latent variable이 다를 경우 서로 다른 행동을 취하게 만들기 위해서이다. Latent variable \(z\)는 보통 원핫인코딩 벡터이지만, continuous vector를 사용하는 연구도 있다.
Skill discovery 방법론들은 latent variable \(z\)에 따라서 \(\pi_\theta(a|s,z)\)가 만들어내는 trajectories가 달라지게 \(\theta\)를 학습시킨다. 예를 들어, latent variable \(z\)가 5차원 원핫인코딩 벡터라면, 정책에 입력될 수 있는 latent vector가 다섯 종류가 있다는 것이므로 다섯 종류의 정책이 있다고 보면 된다. 그리고 각 정책이 만들어내는 trajectory가 서로 다르게 latent conditioned 정책이 학습된다고 생각하면 된다. 각 latent variable마다 에이전트들의 행동 양상들이 달라지는 데, 특정 latent variable에서는 뭔가 유의미한 행동을 보이기도 한다. 따라서 이 latent variable 또는 latent-conditioned 정책 자체를 skill이라고 부른다. Skill discovery 알고리즘들은 대부분 mutual information을 사용하여 위의 내용들을 구현한다. 따라서 skill discovery 분야를 연구하기 위해서는 mutual information, entropy, KL divergence 등 정보 이론과 variational inference를 알고 있으면 좋다.
가장 직관적이고 기초가 되는 연구로는 DIAYN [9]이 있고, successor features를 latent variable로 사용하는 VISR [10]과 APS [11]가 있다. 최신 연구로는 DISCO-DANCE [12], LSD [13], METRA [14] 등이 있다. 다양한 skill discovery 알고리즘들이 찾아낸 skill이 궁금하다면 METRA의 project page를 참고하면 좋을 것이다.
20.2. Unsupervised RL의 활용#
20.2.1. Pretraining \(\rightarrow\) Fine-tuning#
Unsupervised RL을 활용하는 가장 대표적인 방법이다. Unsupervised RL 연구들의 성능을 비교할 때 많이 사용되는 검증 방법이기도 하다. 아래는 Proto RL [8]이라는 pure exploration 논문에 나와 있는 그림이다. 로봇의 종류에 따라 Walker와 Reach Duplo 도메인이 있고, 각 도메인에서 보상함수를 어떻게 정의하느냐에 따라서 4개의 tasks가 존재하는 상황이다.
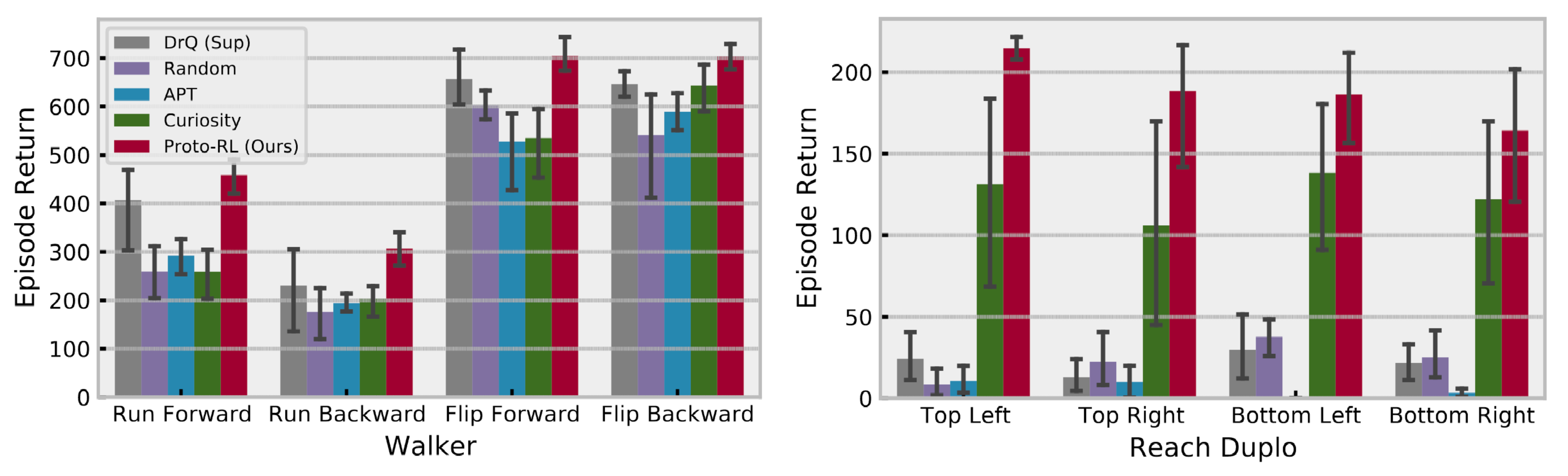
그림에서 회색과 빨간색 막대만 비교하면 된다. 회색 막대는 이미지 상태공간의 환경에서 많이 사용되는 DrQ 알고리즘을 unsupervised pretraining 없이 task reward를 사용해서 1M steps 동안 학습한 결과이다. 나머지 막대들은 첫 500K steps 동안 unsupervised RL로 네트워크 pretraining을 하고, 이후 500K 동안은 DrQ 알고리즘을 사용해서 task rewards를 최대화하도록 fine-tuning한 것이다. 그 중 빨간색 막대가 Proto RL 알고리즘이다. Task rewards를 사용해서 바로 학습할 때보다 첫 50만 번을 보상함수 없이 unsupervised pretraining을 하고, 나머지 50만 번을 보상함수를 관찰하며 fine-tuning 했을 때, 성능이 훨씬 좋은 것을 확인할 수 있다. 심지어 한 도메인에 대해서 한 번 unsupervised pretraining 해놓으면, 보상함수만 바꿔가며 원하는 task에서 적은 상호작용만으로 좋은 성능을 얻을 수 있으니 sample efficient하다고 불 수 있다.
20.2.2. Offline RL을 위한 데이터셋 생성#
Unsupervised RL 동안 모아놓은 데이터셋을 활용하는 방법도 있다. ExORL [15]은 unsupervised RL을 통해 데이터셋 \(\left\{ (x_i, a_i, x_{i+1}) \right\}_{i=1}^N\)을 만들어 놓고, 이후에 풀고자 하는 task의 보상함수로 데이터셋에 레이블을 부여하여 offline 데이터셋 \(\left\{ (x_i, a_i, r_i, x_{i+1}) \right\}_{i=1}^N\)을 만든 다음 offline RL을 적용하는 연구를 했다.

Fig. 20.1 ExORL#
위 그림은 ExORL 논문에 나와 있는 그림이다. 좌측 상단의 그림은 실험에 사용된 PointMass Maze 환경을 보여준다. 주황색 점이 에이전트가 제어해야 할 대상이다. 그리고 나머지 그림들은 각각 unsupervised RL 알고리즘을 사용해서 모은 데이터셋의 state distribution을 보여준다. 참고로 ICM부터 APT는 pure exploration 방법론이고, APS와 DIAYN은 skill discovery 방법론이며, SMM은 2개의 특징을 모두 갖고 있는 알고리즘이다.
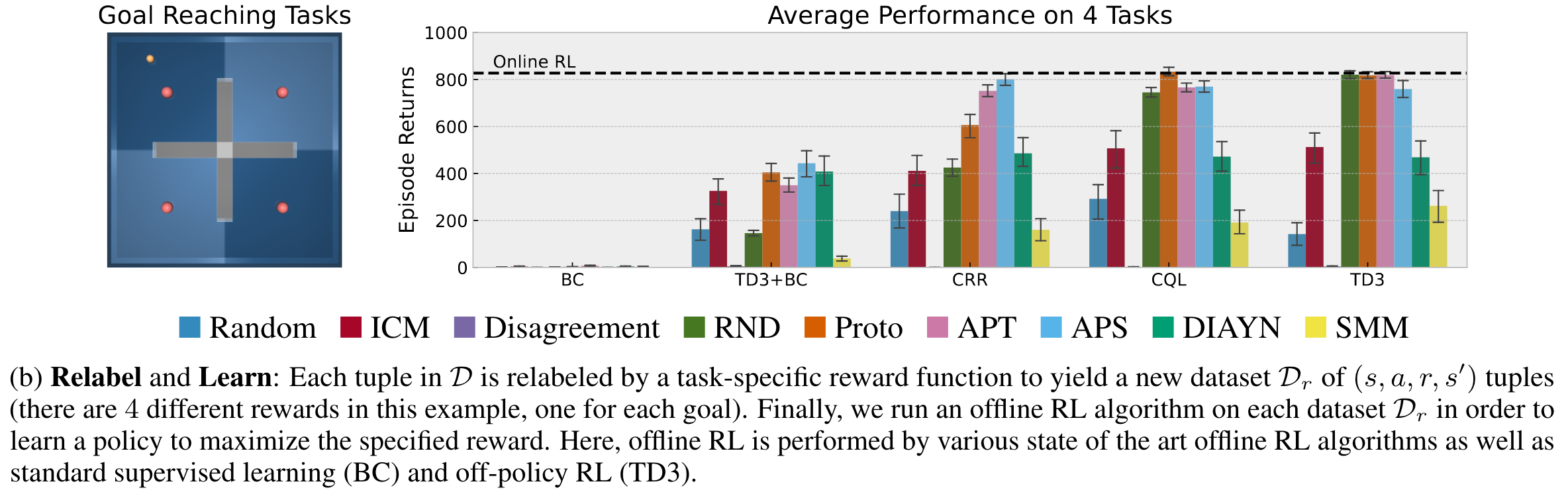
위 그림은 모아 놓은 데이터셋에 각 task에 맞는 보상함수를 부여한 후 offline RL로 에이전트를 훈련시켰을 때의 성능을 보여준다. Downstream task는 주어진 목표 지점에 도착하는 것이며, 왼쪽 그림에서 빨간색 점이 목표 지점이고 빨간색 점 하나당 하나의 task를 나타낸다. 목표 지점에 도착하면 보상을 받고 그 외에는 보상은 없다. 우측 그래프는 4개의 offline RL 알고리즘 (BC, TD3+BC, CRR, CQL)과 하나의 off-policy RL 알고리즘 TD3로 offline RL을 한 후 online 환경에 대해 evalaution한 결과이다.
여기서 신기한 점은 unsupervised RL로 만든 offline 데이터셋의 경우 offline RL 알고리즘을 사용하지 않고 TD3와 같은 그냥 off-policy RL 알고리즘을 적용했을 때 성능이 더 잘 나온다는 것이다. Offline RL 알고리즘들은 최대한 데이터셋 내의 상태와 행동에 머무르도록 에이전트를 regularization 한다. 데이터셋에 없는 상태에 도달하거나 행동을 취한다면 너무나 당연하게도 네트워크의 출력 결과에 에러가 많을 것이기 때문이다. 한편, unsupervised RL 알고리즘은 최대한 많은 상태와 행동을 탐험하면서 데이터셋을 만들었기 때문에 네트워크가 대부분의 상태와 행동에 대해서 에러가 적은 예측 결과를 내뱉을 수 있을 것이다. 그래서 굳이 offline RL 알고리즘이 아니더라도 좋은 성능을 받을 수 있는 것이다. ExORL은 실제 보상함수를 알아야 한다는 강한 가정이 들어가는 연구였지만 재밌는 논문이었다.
20.2.3. 개발한 게임에서 버그 찾기#
이번에는 조금 더 현실 세계에서 적용할만한 사례를 가지고 왔다. 바로 개발한 게임 환경에 버그가 있는지 없는지 스스로 테스트해주는 사례이다 [16]. 논문의 제목은 “Improving Playtesting Coverage via Curiosity Driven Reinforcement Learning Agents”이다.

위 그림은 테스팅에 사용된 게임을 보여준다. \(500\text{m} \times 500\text{m} \times 50\text{m}\) 크기의 광활한 맵에 에이전트가 unsupervised RL로 탐험을 하여 버그를 찾거나 제작자의 의도와 다르게 문제를 해결하는 방법 등을 찾아내게 된다. 원 논문에 재미있는 발견 사례들이 많이 있지만, 그 중에서 재밌는 버그를 찾은 사례 하나를 소개하겠다.

왼쪽 그림이 버그가 발생한 위치인데, 언뜻보면 그냥 큰 돌 앞에 에이전트가 서있는 것처럼 보인다. 하지만 사실 지금 에이전트는 개발자의 실수로 만들어진 빈틈에 낑겨 있는 상태이다 (인간이 미안해). 빈틈에 낑긴 상태로 에이전트가 움직이니 물리 엔진에서 수치적 오류가 누적되어 그런지 에이전트가 하늘로 날아가 버리게 된다. 이런 에이전트의 버그적인 움직임이 오른쪽 그림의 파란색 점과 하얀색 선으로 나타나있다. 높이도 날아간다.
이 외에 강화학습 에이전트가 찾은 버그들을 보고 싶으신 분들은 유튜버 Two Minute Papers의 영상을 참고하면 좋을 것 같다.
20.3. 끝맺음말#
Unsupervised RL 분야는 보면 볼수록 매력 있는 것 같다. 특히, 보상함수 없이 환경에서 우리가 활용할 수 있는 정보들을 발견 (discover)하는 것을 목표로 한다는 그 철학이 굉장히 매력적이다. 그리고 상대적으로 발전이 필요한 부분들이 많다는 것도 연구자 입장으로서 매력적이다. 예를 들어, unsupervised RL 알고리즘 개발도 하나의 연구 분야가 될 것이고, unsupervised RL로 얻어낸 정보들 (경험 데이터, 네트워크 파라미터 등 다양하게 정의될 수 있는)을 활용하는 방법 개발도 연구 분야가 될 수 있을 것이다. 마지막으로, 사용자가 제작한 환경에서 무엇을 할 수 있을지 unsupervised RL이 찾아줄 수 있다는 것도 매력적이다. 아직 강화학습에서 어떤 분야를 연구할지 정하지 못한 분들은 unsupervised RL을 파보는 것도 정말 좋을 것 같다.
이상으로 unsupervised RL에 대한 소개 글을 마치도록 할 것이다. 활발히 연구되는 분야인만큼 이 포스팅도 지속적으로 업데이트될 예정이다. 다음 주제로는 successor features를 다뤄 볼 예정이며 빠르면 2024년 5월 말에 오도록 하겠다.