

이번 포스팅에서는 REINFORCE 알고리즘을 Pendulum 환경에 적용해볼 예정이다. 다른 대부분의 REINFORCE 구현 예제들이 이산행동공간을 갖는 CartPole 환경을 사용하고 있기 때문에 연속행동공간을 풀고 싶은 분들에게는 어딘가 채워지지 않은 불만족감이 있었을 것이다. 그 불만족감을 이 포스팅으로 만족감으로 바꿔드리고 싶다.
하지만 그냥 REINFORCE로는 Pendulum에서 좋은 성능을 얻기 어렵다. 따라서 이번 포스팅에서는 REINFORCE에서 시작해서 알고리즘적 개선과 코드구현적 디테일을 추가하여 성능을 점점 올려볼 것이다. 이번 포스팅에서 다뤄볼 기술들은 다음과 같다.
- REINFORCE 구현
- REINFORCE with baseline 구현
- Orthogonal initialization
그럼 가장 먼저 연속행동공간을 위한 REINFORCE를 먼저 구현을 해보도록 하자. 이 포스팅의 모든 코드는 내 머릿속에서 나온 것이 단 하나도 없으며 정말 다양한 코드들을 보면서 만들었다. 참고한 모든 코드들은 맨 아래 참고문헌에 남겨놓았다.
REINFORCE 구현
Policy 네트워크 정의
Policy 네트워크로는 간단한 MLP를 사용할 예정이며, 연속행동공간을 다루기 위하여 정규분포의 평균과 표준편차를 출력하는 네트워크를 만들 것이다. 네트워크가 출력한 평균과 표준편차를 사용하여 정규분포를 만들고, 그 정규분포에서 행동을 샘플링할 것이다. 일반적인 코드를 작성하기보다는 간결한 코드를 작성하기 위하여 클래스의 인자들을 최소화했다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class Policy(nn.Module):
def __init__(self, state_dim, action_dim):
super(Policy, self).__init__()
self.input_layer = nn.Linear(state_dim, 512)
self.mu_layer = nn.Linear(512, action_dim)
self.log_std_layer = nn.Linear(512, action_dim)
def forward(self, x):
x = F.relu(self.input_layer(x))
mu = self.mu_layer(x)
log_std = torch.tanh(self.log_std_layer(x))
return mu, log_std.exp()
REINFORCE 에이전트
REINFORCE.act()메서드는 환경과의 상호작용을 위한 메서드이고, 훈련을 위한 메서드가 아니다. 따라서@torch.no_grad()데코레이터를 통해서 굳이 연산 그래프 (computational graph)를 만들지 않는다. 그리고, 훈련 데이터를 수집할 때는 정규분포에서 탐색을 보장하기 위해서 행동을 정규분포에서 샘플링한다. 반면, 성능 평가 목적으로 환경과 상호작용할 때는 정규분포의 평균값에 해당하는 행동을 선택하요 exploitation을 수행한다. 정규분포에서 샘플링된 행동을 tanh를 통해 -1과 1사이 값으로 만들어준다.REINFORCE.learn()메서드는 한 에피소드가 종료된 후 정책 네트워크를 훈련시키는 메서드이다.REINFORCE.process()메서드는 매 타임스탭마다 할 일과 매 에피소드마다 할 일을 정의하는 메서드이다. REINFORCE의 경우 매 타임스탭 얻은 데이터를 저장하면 되고, 매 에피소드마다 정책 업데이트 및 버퍼 초기화를 하면 된다.
class REINFORCE:
def __init__(self, state_dim, action_dim, gamma=0.9):
self.policy = Policy(state_dim, action_dim)
self.gamma = gamma
self.policy_optimizer = torch.optim.Adam(self.policy.parameters(), lr=0.0003)
self.buffer = []
@torch.no_grad()
def act(self, s, training=True):
self.policy.train(training)
s = torch.as_tensor(s).float()
mu, std = self.policy(s)
z = torch.normal(mu, std) if training else mu
a = torch.tanh(z)
return a.numpy()
def learn(self):
# [(s_1, a_1, r_1), (s_2, a_2_r_2), ... ]를 (s_1, s_2, ...), (a_1, a_2, ...), (r_1, r_2, ...)로 변환
s, a, r = map(np.stack, zip(*self.buffer))
# G_t 만들어주기
G = np.copy(r)
for t in reversed(range(len(r) - 1)):
G[t] += self.gamma * G[t + 1]
s, a, G = map(lambda x: torch.as_tensor(x).float(), [s, a, G])
G = G.unsqueeze(1) # 열벡터 만들어주기
# log prob 만들기
mu, std = self.policy(s)
m = torch.distributions.Normal(mu, std)
z = torch.atanh(torch.clip(a, -1.0 + 1e-7, 1.0 - 1e-7)) # torch.atanh(-1.0), torch.atanh(1.0)은 각각 -infty, infty라서 clipping 필요
log_prob = m.log_prob(z)
# 손실함수 만들기 및 역전파
policy_loss = - (log_prob * G).mean()
self.policy_optimizer.zero_grad()
policy_loss.backward()
self.policy_optimizer.step()
def process(self, s, a, r, done):
self.buffer.append((s, a, r))
if done:
self.learn()
self.buffer = []
실험 환경 만들기
심층강화학습의 경우 훈련 과정이 굉장히 불안정하다. 분명히 같은 네트워크, 같은 강화학습 알고리즘을 사용해도 랜덤 시드마다 학습 과정과 결과가 엄청 크게 달라진다. 그래서 서로 다른 두 강화학습 알고리즘을 비교하기 위해서는 여러 랜덤시드에 대해서 실험을 진행하고 학습 곡선에 대한 다양한 통계를 비교하는 것이 중요하다. 실험을 여러번 반복하는 만큼 실험 한번에 소요되는 시간이 굉장히 길다. 하지만 실험 결과에 신뢰성을 부여하기 위해서는 이렇게 실험을 여러번 반복하고, 실험 결과에 대한 여러 통계량을 제시해야 한다.
따라서 앞으로 있을 매 실험에서는 10개의 랜덤시드에 대해서 실험을 진행할 것이며, 각 실험은 총 1,000,000번 환경과 상호작용하면서 에이전트를 훈련시킬 것이다. 매 5,000번마다 에이전트의 성능평가가 실행되며, 성능 지표로는 에피소드를 10번 진행하여 얻은 평균 누적 보상을 사용할 것이다.
num_seeds = 10
max_iterations = 1000000
eval_intervals = 5000
eval_iterations = 10
다음 seed_all 함수를 통해 언제 코드를 돌려도 같은 결과를 얻게 만들 것이다. seed_all 함수는 이번 실험 뿐만 아니라 두고 두고 사용할 수 있기 때문에 Github gist 등에 코드 조각을 저장해놓으면 굉장히 유용하다.
import torch
import random
import numpy as np
def seed_all(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
다음은 매 5,000번마다 진행되는 에이전트의 성능 평가를 위한 함수이다. 훈련에 사용한 환경의 랜덤시드와 다른 랜덤시드를 사용하기 위하여 env.seed(seed + 9999)를 넣어주었다. 에이전트의 행동 (REINFORCE.act()) 메서드는 마지막에 torch.tanh를 사용해서 -1과 1사이의 행동을 취한다. 하지만, Pendulum-v0의 행동공간이 -2.0부터 2.0이기 때문에 env.step(2.0 * a)를 사용해주었다.
def evaluate(env_name, agent, seed, eval_iterations):
env = gym.make(env_name)
env.seed(seed + 9999)
scores = []
for _ in range(eval_iterations):
s, done, ret = env.reset(), False, 0
while not done:
a = agent.act(s, training=False)
s_prime, r, done, _ = env.step(2.0 * a)
ret += r
s = s_prime
scores.append(ret)
env.close()
return round(np.mean(scores), 4)
실험 로깅으로는 Weight & Bias (wandb)를 사용할 것이다. wandb를 설치하기 싫어서 뒤로가기 누를 예정인 당신! 그 귀찮음을 잠시 눌러두고 이번 기회에 wandb를 한번 사용해보는 것은 어떤가? 절대 후회 없을 것이다. 이 포스팅에 나오는 훈련 과정 그래프는 모두 wandb에서 “자동”으로 그려주는 것이다. 물론, 이 포스팅에서 wandb를 설치하고 사용하는 방법에 대해서는 다루지 않는다. 하지만, pip install wandb 한 줄로 설치 가능하며, wandb 회원가입하고 1회만 로그인하면 된다. 나의 딥러닝 인생은 wandb를 알기 전과 후로 나뉜다고 말해도 과언이 아닐 정도로 나에게 큰 영향을 준 패키지이니 꼭 사용해보는 것을 권장한다.
import gym
import wandb
env_name = 'Pendulum-v0'
agent_name = 'REINFORCE'
for seed in range(num_seeds):
wandb.init(project=env_name, group=agent_name, name=f'seed {seed}')
seed_all(seed)
env = gym.make(env_name)
env.seed(seed)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
agent = REINFORCE(state_dim, action_dim)
s, done, ret = env.reset(), False, 0
for t in range(1, max_iterations + 1):
a = agent.act(s)
s_prime, r, done, _ = env.step(2.0 * a)
agent.process(s, a, r, done)
s = s_prime
if done:
s, done, ret = env.reset(), False, 0
if t % eval_intervals == 0:
score = evaluate(env_name, agent, seed, eval_iterations)
wandb.log({'Steps': t, 'AvgEpRet': score})
wandb.finish()
결과 확인
위의 코드를 실행하여 얻은 10개 시드에 대한 실험 결과를 살펴보도록 하자. 실험 결과는 굉장히 실망스럽겠지만, wandb 미친 기능들은 정말 놀라울 것이다. 먼저, https://wandb.ai/home에서 username/Pendulum-v0 프로젝트에 들어가보면 다음과 같은 그래프를 볼 수 있을 것이다. 각 시드별로 학습 곡선이 그려진 모습이다.
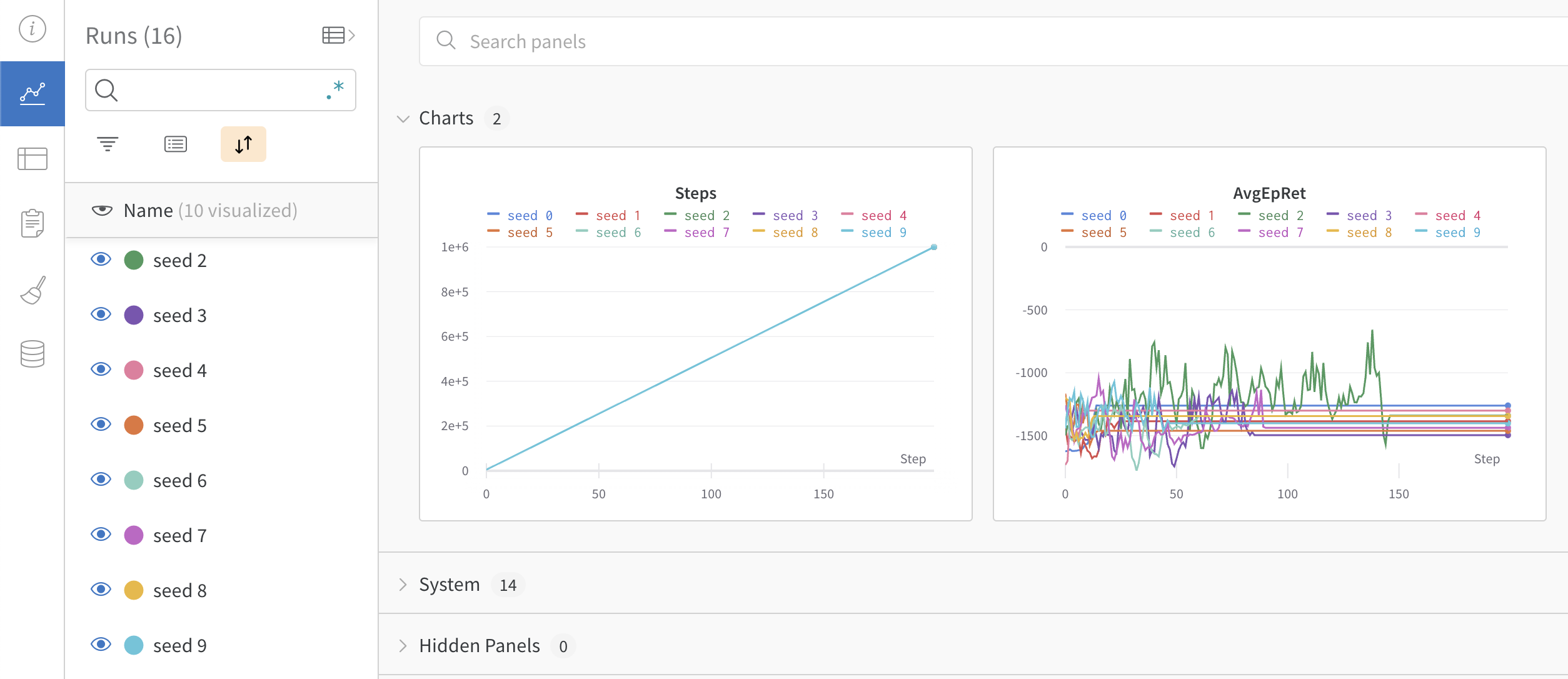
좌측 검색바 아래 가운데 있는 Group 버튼을 누른 후 No grouping으로 되어 있는 곳을 클릭하여 Group으로 설정해주자
그러면 다음 그림과 같이 10개의 실험 결과들이 하나의 그래프로 요약된다. 노란색 실선은 각 Steps에서의 10개 실험에 대한 평균 누적 보상이고, 색칠된 영역은 10개 실험 중 min값과 max값이다. min/max로 구간을 많이 표시하기도 하지만 표준편차로 구간을 표현하기도 한다. 그래프의 우측에 연필 모양을 눌러서 변경해줄 수 있다.
연필 모양을 누른 후 Grouping으로 들어가서 Range를 Std Dev로 변경해주자.
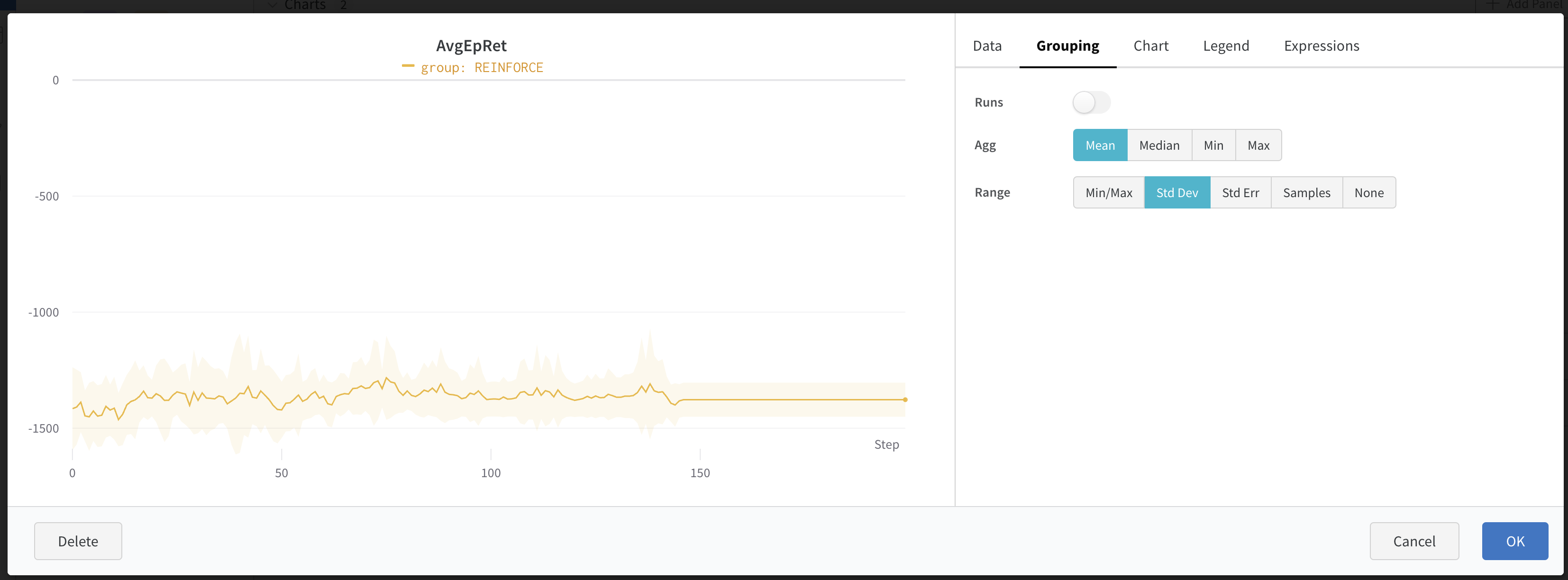
어떤가? wandb를 사용하지 않은 지난 날들이 후회되지 않는가? wandb의 엄청난 기능에 가려져 있었지만, 이제 우리의 처참한 REINFORCE 성능을 살펴보자.
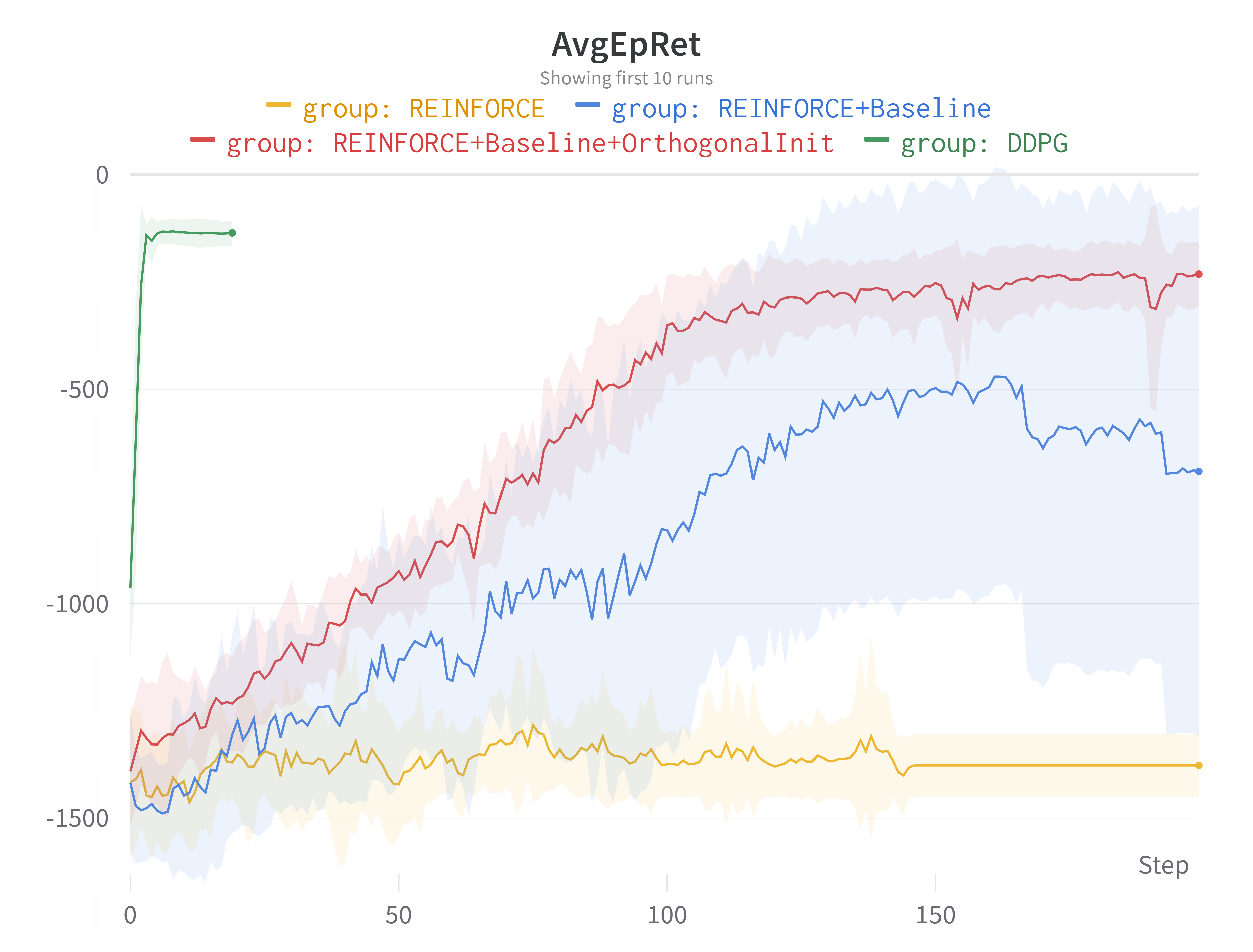
Pendulum-v0 환경은 이론상 에피소드 동안 최대 0의 누적 보상을 받을 수 있다. 하지만 초기 상태에 따라 누적 보상이 절대 0에 도달할 수 없기도 하다. 그래서 누적보상이 0에 가까울 수록 좋다는 것만 기억하자. 무튼, REINFORCE의 경우 평균 누적보상이 약 -1,500이며, 총 1,000,000번의 스탭 동안 훈련이 전혀되지 않은 것을 확인할 수 있다. REINFORCE가 아무리 가장 기본이 되는 에이전트라고 해도, Pendulum 또한 가장 기본이 되는 환경인데, 전혀 풀어내지 못한 모습이다. 하지만 앞으로 알고리즘 개선과 코드 개선을 통해 이 REINFORCE를 개과천선시켜볼 것이다.
REINFORCE + Baseline
REINFORCE은 Pendulume 제어하는 방법을 전혀 학습하지 못했다. 그 이유가 무엇이다라고는 확실하게 말하지 못할 것 같다. 다행히도 REINFORCE에 baseline을 추가하면 어느 정도 Pendulum을 제어할 수 있게 된다.
앞으로 나올 코드는 지금까지 작성한 코드에 플러스 알파되는 코드이다. 중복되는 실험 환경 코드는 작성하지 않았다. 또 필자는 하나의 주피터 노트북에서 모든 실험을 진행하지 않았고, 알고리즘 (REINFORCE, REINFORCE + baseline, REINFORCE + baseline + …) 마다 각각 다른 주피터 노트북에 작성하여 실험하였다.
State value function 근사를 위한 네트워크 정의
State value function 네트워크는 상태를 입력 받아 상태가치함수를 출력해주는 함수이다. 따라서 입력 차원은 상태의 차원이 되어야 하고, 출력 차원은 1이어야 한다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class StateValue(nn.Module):
def __init__(self, state_dim):
super(StateValue, self).__init__()
self.input_layer = nn.Linear(state_dim, 512)
self.output_layer = nn.Linear(512, 1)
def forward(self, x):
x = F.relu(self.input_layer(x))
x = self.output_layer(x)
return x
REINFORCE with Baseline 에이전트
REINFORCE with Baseline 에이전트는 REINFORCE에서 policy gradient가 살짝 달라진다. 즉, $\mathbb{E}_t \left[ G_t \nabla_{\theta} \log \pi_{\theta}(a_t|s_t) \right]$에서 $\mathbb{E}_t \left[ \left(G_t - v_{\phi}(s_t) \right) \log \nabla_{\theta} \pi_{\theta}(a_t|s_t) \right]$로 변경된다. 여기서 상태가치함수를 추정하기 위해 또 다른 딥러닝 네트워크 $v_{\phi}$를 사용한다. $v_{\phi}(s_t)$는 $s_t$에서 정책을 따랐을 때 얻게 되는 return $G_t$의 기댓값이다. 따라서 상태가치함수 네트워크를 훈련시키기 위한 목적함수로는 $\frac{1}{T}\sum_{t=1}^{T} \left( G_t - v_{\phi}(s_t)\right)^2$을 사용한다.
정책 네트워크를 업데이트할 때 주의할 점이 있다. $\left(G_t - v_{\phi}(s_t) \right)$에서 $v_{\phi}(s_t)$는 지도학습에서 레이블에 해당하는 부분으로서 학습가능한 파라미터가 아닌 데이터 값이어야 한다. 따라서 v.detach()를 해줘야 한다. 물론, 이 경우 $\theta$와 $\phi$가 서로 간섭을 일으키지 않지만, 나중에 Actor Critic에서 사용하는 TD target의 경우 r + self.gamma * v(s_prime) - v(s) 꼴이 되는데, 이 경우 v(s_prime).detach()를 해주지 않는다면 이론과 맞지 않은 파라미터 업데이트가 일어나게 된다. 강화학습에서 타겟은 항상 학습가능한 파라미터가 아니라 데이터값으로 받아들여야 한다.
act() 메서드와 process() 메서드는 REINFORCE 에이전트와 완전히 똑같으므로 아래 코드처럼 REINFORCE를 상속 받아서 생략할 수 있다.
class BaselineREINFORCE(REINFORCE):
def __init__(self, state_dim, action_dim, gamma=0.9):
self.policy = Policy(state_dim, action_dim)
self.value = StateValue(state_dim)
self.gamma = gamma
self.policy_optimizer = torch.optim.Adam(self.policy.parameters(), lr=0.0003)
self.value_optimizer = torch.optim.Adam(self.value.parameters(), lr=0.0003)
self.buffer = []
def learn(self):
# [(s_1, a_1, r_1), (s_2, a_2_r_2), ... ]를 (s_1, s_2, ...), (a_1, a_2, ...), (r_1, r_2, ...)로 변환
s, a, r = map(np.stack, zip(*self.buffer))
# G_t 만들어주기
G = np.copy(r)
for t in reversed(range(len(r) - 1)):
G[t] += self.gamma * G[t + 1]
s, a, G = map(lambda x: torch.as_tensor(x).float(), [s, a, G])
G = G.unsqueeze(1) # 열벡터 만들어주기
# log prob 만들기
mu, std = self.policy(s)
m = torch.distributions.Normal(mu, std)
z = torch.atanh(torch.clip(a, -1.0 + 1e-7, 1.0 - 1e-7)) # torch.atanh(-1.0), torch.atanh(1.0)은 각각 -infty, infty라서 clipping 필요
log_prob = m.log_prob(z)
# 정책 손실함수 만들기 및 역전파
v = self.value(s)
policy_loss = -(log_prob * (G - v.detach())).mean()
self.policy_optimizer.zero_grad()
policy_loss.backward()
self.policy_optimizer.step()
# 상태가치함수 손실함수 만들기 및 역전파
value_loss = F.mse_loss(v, G)
self.value_optimizer.zero_grad()
value_loss.backward()
self.value_optimizer.step()
이전에 작성한 실험 코드에서 다음 두 가지만 수정하고 실험을 돌려보았다.
agent_name = 'REINFORCE+Baseline'
for seed in range(num_seeds):
wandb.init(project=env_name, group=agent_name, name=f'seed {seed}')
(중략)
agent=BaselineREINFORCE(state_dim, action_dim)
(후략)
실험 결과
REINFORCE with Baseline 에이전트의 실험 결과는 다음과 같다. Pendulum 제어를 전혀 못했던 과거에서 벗어나, 이제 점점 제어하는 방법을 배워가는 모습을 확인할 수 있다. 이제 “뭔가 학습을 하긴 했구나”하는 생각이 드는 학습 곡선이 나타났다. 평균 누적 보상이 가장 높은 시점은 약 -500 정도되는데, 확실히 높은 누적 보상이라고는 할 수 없다. 이 포스팅에 남기지는 않았지만, 에이전트가 Pendulum을 제어하는 장면을 시각적으로 살펴보면 꽤 잘 한다. 초기 상태가 어떻든 결국은 Pendulum을 세우는데 성공한다. 다만, 짧은 순간 안에 세우지는 못하고, Pendulum이 떨어지면서 발생하는 관성을 사용하여 Pendulum을 점점 올린다.
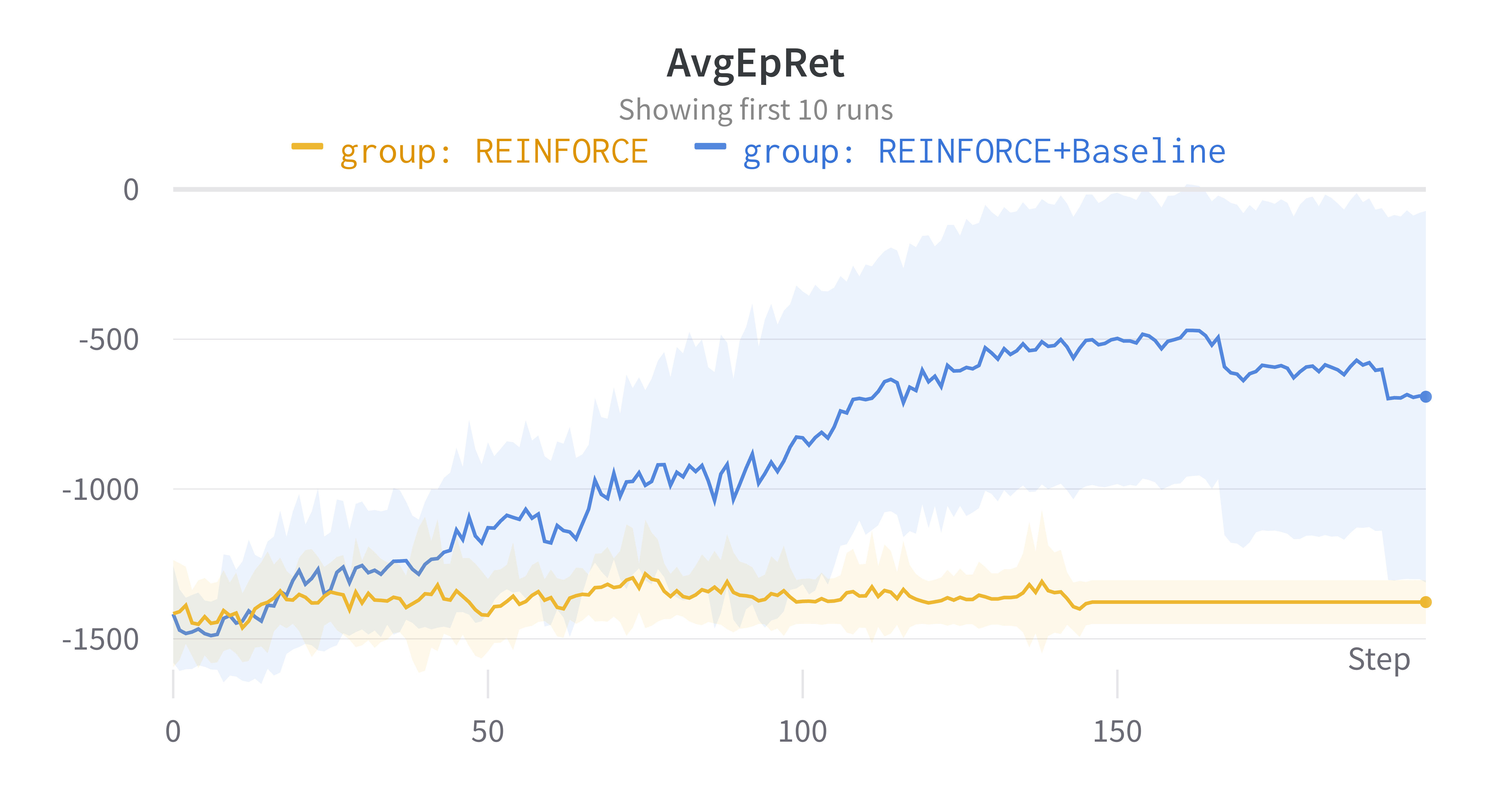
평균 보상 외에 눈 여겨 볼 점은 학습이 진행될수록 신뢰구간이 굉장히 커진다는 것이다. 왜 이렇게 누적보상의 표준편차가 큰지 한번 확인해보자. wandb 좌측의 결과 목록에서 Group:REINFORCE+Baselie을 클릭하면 시드별로 그려진 그래프를 따로 확인할 수 있다. 실험 결과의 큰 분산의 이유는 다음 2가지가 있었다.
- 아예 학습을 하지 못하여, 학습 동안 내내 -1,000 이하를 유지했던 실험
- 학습을 잘 해왔는데 갑자기 막판에 알 수 없는 이유로 갑자기 누적 보상이 -1,000 이하로 떨어진 실험
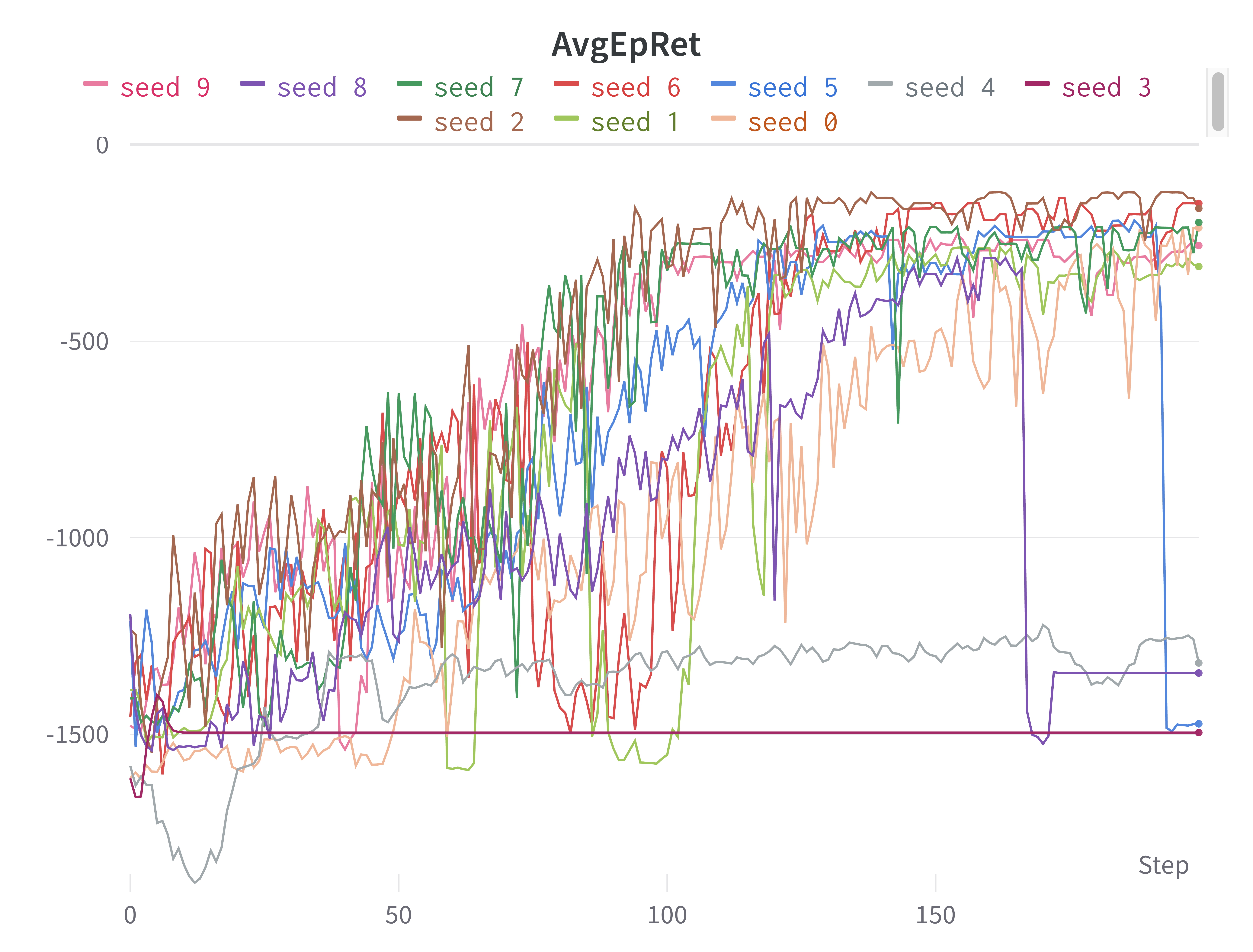
강화학습 코딩을 하다보면 위의 2가지 이유가 참 많이 발생하는데, 그 원인을 알기가 너무 어렵다. 이번 포스팅을 작성하는 동안에 2번 문제를 해결하기 위해 원인을 생각해보고 개선을 해보았는데 여전히 문제가 지속됐었다. 가장 합리적인 의심으로, policy gradient의 $\nabla \log \pi(a | s)$ 텀이 확률이 0에 가까울수록 값이 극도로 커진다는 것을 생각해보았다. 그레디언트 값이 극도로 커지니 파라미터 업데이트가 크게 일어나 에이전트의 성능이 아예 바뀌어버린 것이라고 생각했다. 그래서 확률에 0.0001 정도 수치를 더해줘서 0이 되는 것을 방지하였으나, 문제가 여전히 지속되었다. 그레디언트 clipping을 하면 이런 현상이 없어질 것이라고 생각이 된다. 하지만 clipping을 적용하면 PPO와 비슷한 알고리즘이 되는 것 같아 실험해보지는 않았다.
(이런 현상이 발생하는 경험적인 원인을 아는 독자분이 계신다면 댓글로 알려주시면 굉장히 감사드리겠습니다.)
REINFORCE + Baseline + orthgonal initialization
마지막으로 네트워크 랜덤 초기화 전략을 바꿔서 누적 보상의 평균 뿐만 아니라 실험 사이의 분산도 획기적으로 줄여보도록 하겠다. 각 레이어의 가중치 행렬은 orthogonal initialization을 사용할 것이고, 편향 벡터 (bias vector)는 0으로 초기화할 것이다.
class Policy(nn.Module):
def __init__(self, state_dim, action_dim):
super(Policy, self).__init__()
self.input_layer = nn.Linear(state_dim, 512)
self.mu_layer = nn.Linear(512, action_dim)
self.log_std_layer = nn.Linear(512, action_dim)
nn.init.zeros_(self.input_layer.bias.data)
nn.init.zeros_(self.mu_layer.bias.data)
nn.init.zeros_(self.log_std_layer.bias.data)
nn.init.orthogonal_(self.input_layer.weight.data, nn.init.calculate_gain('relu'))
nn.init.orthogonal_(self.mu_layer.weight.data, nn.init.calculate_gain('linear'))
nn.init.orthogonal_(self.log_std_layer.weight.data, nn.init.calculate_gain('tanh'))
def forward(self, x):
x = F.relu(self.input_layer(x))
mu = self.mu_layer(x)
log_std = torch.tanh(self.log_std_layer(x))
return mu, log_std.exp()
import torch
import torch.nn as nn
import torch.nn.functional as F
class StateValue(nn.Module):
def __init__(self, state_dim):
super(StateValue, self).__init__()
self.input_layer = nn.Linear(state_dim, 512)
self.output_layer = nn.Linear(512, 1)
nn.init.zeros_(self.input_layer.bias.data)
nn.init.zeros_(self.output_layer.bias.data)
nn.init.orthogonal_(self.input_layer.weight.data, nn.init.calculate_gain('relu'))
nn.init.orthogonal_(self.output_layer.weight.data, nn.init.calculate_gain('linear'))
def forward(self, x):
x = F.relu(self.input_layer(x))
x = self.output_layer(x)
return x
이전에 작성한 실험 코드에서 다음만 수정하고 실험을 돌려보았다.
agent_name = 'REINFORCE+Baseline+OrthogonalInit'
for seed in range(num_seeds):
(후략)
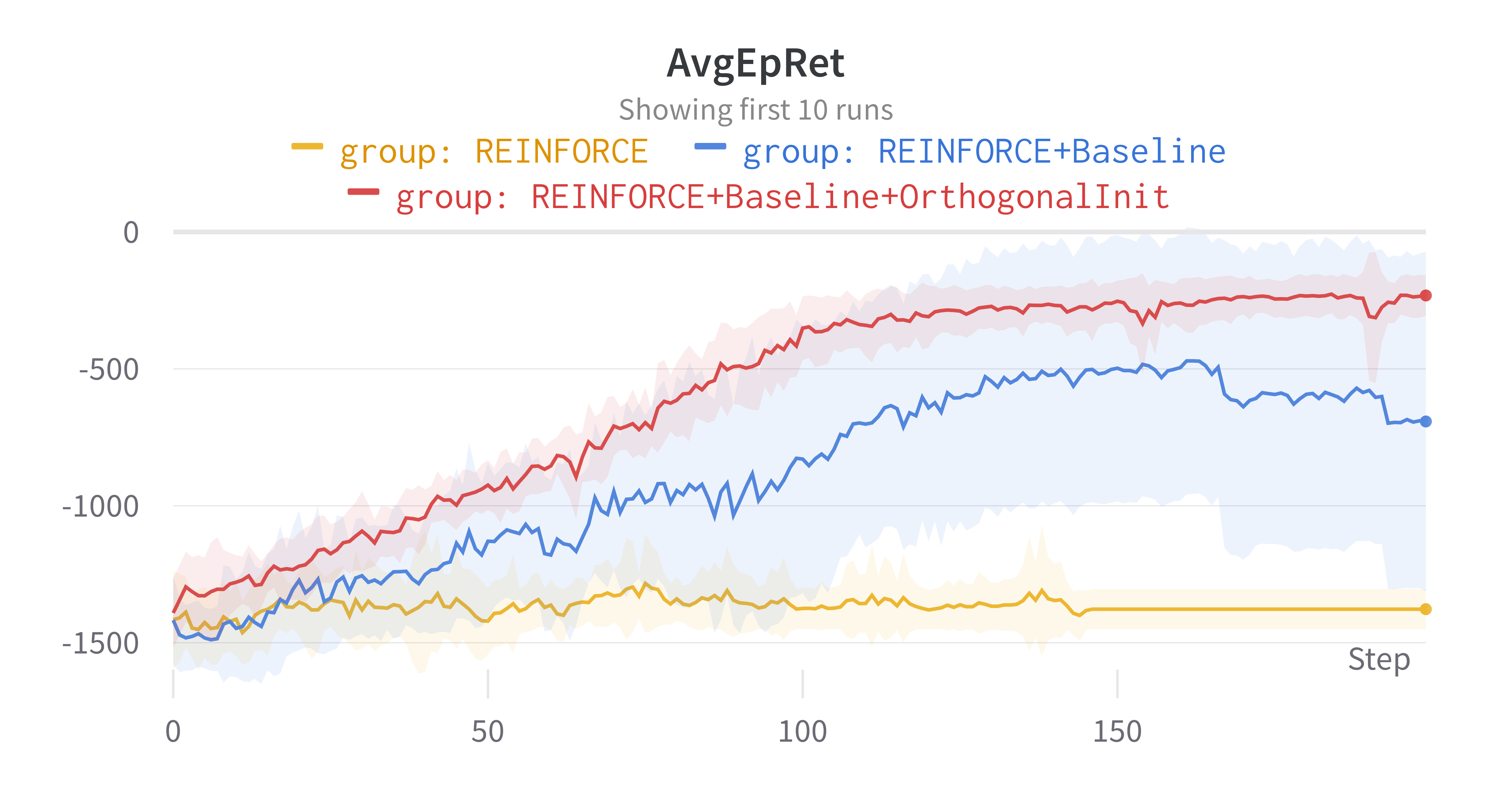
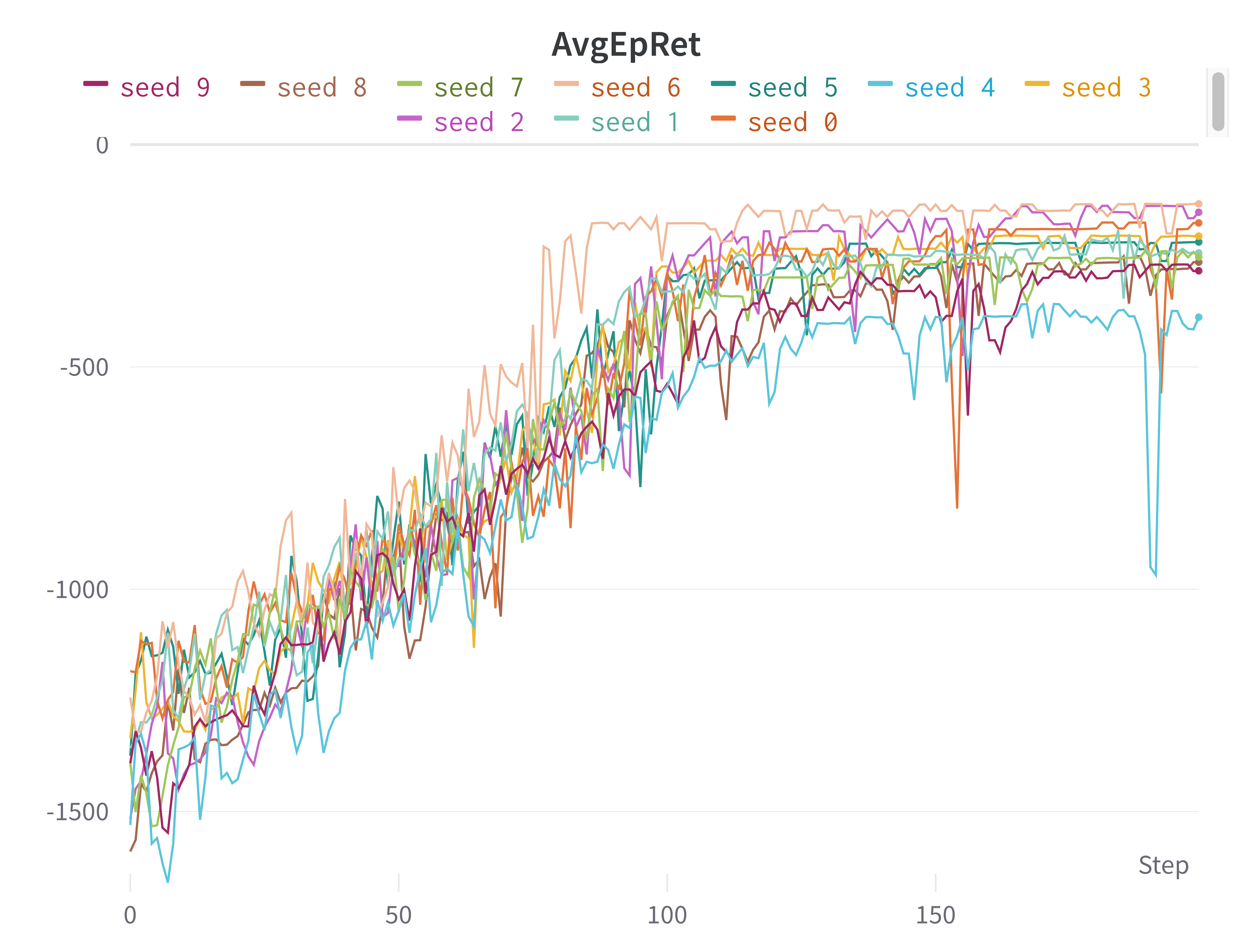
성능이 훨씬 향상됐을 뿐만 아니라, 학습 곡선의 분산도 굉장히 낮아진 것을 확인할 수 있었다. 가중치 초기화가 중요하다지만 이렇게까지 큰 성능 향상을 만들어낼지는 전혀 알지 못했다. 심지어, torch.nn.Linear는 기본적으로 Kaiming He 초기화를 사용하고 있는데도 말이다. 각 시드에서의 학습 곡선은 아래와 같다. 대부분의 시드에서 성공적으로 Pendulume 제어하는 방법을 학습할 수 있었다.
이 포스팅에 첨부하지는 않았지만, torch.nn.Linear의 기본값에서 다음 세 가지 옵션을 해봤는데, 1번은 학습이 REINFOCE + Baseline이 비해 감소하고, 2번은 성능 향상이 조금 있지만 분산은 여전했다. 3번처럼 했을 때 성능이 많이 증가하고, 분산도 줄어들었다.
- 편향 벡터만 영벡터로 초기화할 때,
- 가중치 행렬만 orthogonal 초기화할 때,
- 가중치 행렬은 orthogonal 초기화하고 편향 벡터는 영벡터로 초기화할 때,
글을 마무리하며
REINFORCE는 굉장히 기본적인 에이전트지만, 다른 에이전트에 사용된 여러 알고리즘적 및 코드구현적 개선을 직접 추가해보고 눈으로 성능 향상을 볼 수 있다는 점에서 굉장히 좋은 것 같다. 앞으로 강화학습을 공부하며 배우게 될 아이디어들도 추가해보고 성능 향상이 유의미하게 있으면 포스팅에 추가하도록 하겠다. 마지막으로 다음 그림을 출품하며 이 포스팅을 마무리하고자 한다.
작품명 ???: 역시 X밥 싸움이 제일 재밌어 ㅋㅋ
참고 문헌
국내에서 정말 훌륭하신 분들이 만드신 코드 [1]~[3]와 Open AI의 [4]를 많이 참고하여 저만의 강화학습 라이브러리 @HiddenBeginner/rl_learner를 만들고 있습니다. 참고한 모든 코드의 작성자들에게 무한한 감사의 인사를 전합니다. 이렇게 대단하신 분들이 많은데, 내가 과연 강화학습 분야로 경쟁력을 갖출 수 있을까 항상 벽을 느끼고 있습니다. 나중에 꼭 직장 동료로서 만나뵙는 날이 찾아오면 좋겠습니다.
