친구가 파이썬, 딥러닝도 모르면서 Grad CAM은 써보고 싶다고 한다. 인중을 때려주고 싶지만, 소중한 뉴비가 이 분야를 이탈하지 않도록 도와주기 위해 이 코드를 작성한다. 시작.
변수 선언 및 라이브러리 불러오기
먼저 나중에 사용할 값들을 변수에 저장해놓자. 다 피가 되고 살이 된다.
input_shape = (28, 28, 1) # 입력 데이터 하나의 크기 (높이, 너비, 채널)
num_classes = 10 # 분류 클래스 개수
필요한 라이브러리들을 불러오자. 오류나면 설치하라.
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import tensorflow as tf
from tensorflow import keras
MNIST 데이터셋 불러오기
케라스 내장 함수를 사용하여 MNIST 데이터를 불러온다. 실전에서는 당신의 데이터를 불러오면 된다.
(X_train, y_train), (X_test, y_test) = keras.datasets.mnist.load_data()
- 데이터가 몇 개나 있나 확인해보자
- 훈련 데이터는 60,000개, 테스트 데이터는 10,000개가 있으며 각 데이터는 $28 \times 28$ 행렬에 0부터 255 사이의 픽셀값이 적혀 있는 사진이다. 클래스 값으로는 0부터 9까지 가질 수 있다.
np.ndarray의shapeattribute는 변수의 크기를 나타낸다.- attribute란? 파이썬에는 객체라는 것이 존재한다. 객체 안에는 데이터도 넣을 수 있고, 함수도 넣을 수 있고, 이것 저것 다 넣을 수 있다. 넘파이 배열 (
np.ndarray)은 객체다. attribute는 객체 안에 저장되어 있는 데이터 중 하나다.
- attribute란? 파이썬에는 객체라는 것이 존재한다. 객체 안에는 데이터도 넣을 수 있고, 함수도 넣을 수 있고, 이것 저것 다 넣을 수 있다. 넘파이 배열 (
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
(60000, 28, 28)
(60000,)
(10000, 28, 28)
(10000,)
데이터 전처리
- CNN은 4차원 텐서 (데이터 개수, 높이, 너비, 채널)를 입력 받는다. 현재
X_train은 채널을 위한 축이 없기 때문에 이를 추가해줘야 한다. - 딥러닝 프레임워크는 32비트
float자료형을 입력 받는다. - 딥러닝 모델을 돌릴 땐, 보통 데이터를 -1과 1사이 값으로 만들어준다.
- 클래스는 원핫인코딩이라는 것을 해줘야 한다.
X_train = X_train[..., np.newaxis]
X_train = X_train.astype(np.float32)
X_train = X_train / 255.0
X_test = X_test[..., np.newaxis]
X_test = X_test.astype(np.float32)
X_test = X_test / 255.0
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
간단한 CNN 모델 만들기
- CNN 모델을 만든다. CNN 먼저 공부하고 오기를 바란다.
def get_basic_cnn(input_shape=(28, 28, 1), num_classes=10):
cnn = keras.models.Sequential([
keras.layers.Conv2D(32, 3, padding='same', activation='relu', input_shape=input_shape),
keras.layers.MaxPool2D(),
keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
keras.layers.MaxPool2D(),
keras.layers.Flatten(),
keras.layers.Dense(num_classes),
keras.layers.Softmax(),
])
return cnn
- 만든 모델은 대충 아래 표처럼 구성되어 있다.
model = get_basic_cnn()
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 32) 320
max_pooling2d (MaxPooling2D (None, 14, 14, 32) 0
)
conv2d_1 (Conv2D) (None, 14, 14, 64) 18496
max_pooling2d_1 (MaxPooling (None, 7, 7, 64) 0
2D)
flatten (Flatten) (None, 3136) 0
dense (Dense) (None, 10) 31370
softmax (Softmax) (None, 10) 0
=================================================================
Total params: 50,186
Trainable params: 50,186
Non-trainable params: 0
_________________________________________________________________
모델의 손실 함수, 최적화 알고리즘, 평가지표 설정
손실 함수란?
- 딥러닝 모델은 복잡해보이지만 그냥 하나의 함수라고 이해하면 된다. $f(x)=ax^2+bx+c$ 와 같은 2차 함수를 예로 들어보자. 입력값 $x$ 하나가 들어가면 출력값 $f(x)$가 나온다. $f(x)$는 $ax^2+bx+c$의 연산을 한다. 이 연산의 결과는 $a, b, c$ 값에 따라 달라진다. 딥러닝은 매우 복잡하게 생긴 함수로 이해하자.
- 위의 예시처럼 딥러닝 모델에는 $a, b, c$ 같은 학습 가능한 파라미터가 있다. 학습한다는 것은 $a, b, c$ 값을 점점 좋은 값으로 설정해준다는 것이다. 우리가 사용할 수 있는 $a, b, c$는 무수히 많을텐데, 좋은 $a, b, c$란 무엇일까?
- 좋은 $a, b, c$란 손실 함수를 최소로 만들어주는 $a, b, c$이다. 데이터를 $x$, 대응하는 정답을 $y$라고 해보자. 우리의 모델의 예측값은 $f(x)$라고 말했다. 그럼 $(y-f(x))$는 무엇이 되는가? 바로 오차가 된다. 우리의 바람은 $f(x)$가 $y$와 최대한 비슷해지는 것이다. 우리는 무수히 많은 $a, b, c$ 선택지 중에서 오차를 가장 작게 만들어주는 $a, b, c$를 찾을 것이다.
- 설명은 하나의 데이터에서 발생한 오차만을 고려했지만, 손실 함수는 보통 모든 데이터의 평균 오차를 최소화하게 된다. 오차는 양수일 수도 있고 음수일 수도 있기 때문에 모든 데이터의 오차를 더하면 양수와 음수가 서로 상쇄될 수 있다. 이를 방지하기 위해 오차 제곱의 평균을 최소화해준다. $\frac{1}{N} \sum_{i=1}^N (y_i - f(x_i))^2$
- 분류 문제에서는 위 손실 함수보다 Cross Entropy라는 손실 함수를 사용한다. 이건 당신이 공부하길 바란다. 하지만 철학을 동일하다. 모델의 예측 값 $f(x)$와 실제 클래스 $y$의 차이를 다 평균낸 것이다.
최적화 알고리즘이란?
- 우리의 목표를 정리하자면 우리의 모델 $f(x)$에 들어있는 학습 가능한 파라미터를 손실 함수를 최소로 만들어주는 녀석들로 설정하고 싶다.
- 학창 시절 함수의 최소값을 구하기 위해 함수를 미분하여 0되는 지점을 모두 조사했었다. 하지만 손실 함수는 굉장히 복잡해서 미분하여 0되는 지점을 계산할 수 없다.
- 그래서 이용하는 것이 최적화 알고리즘이다. 다 됐고, 손실함수를 낮추는 방향으로 학습 가능한 파라미터 $a, b, c$를 조금씩 조정하는 알고리즘이다. 그냥 adam 쓰셈
평가지표란?
- 손실 함수는 오차들의 평균이라고 했다. 그 값을 사람이 보기엔 의미를 해석하기 어렵다. 평가 지표는 사람이 이해하기 쉬운 다른 좋은 지표이다.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics='acc')
모델 학습
- 데이터를 직접 넣어서 $f(x)$를 구하고, 오차를 구하며, 모델 파라미터를 조정하는 과정이다.
history = model.fit(X_train, y_train, validation_split=0.2, epochs=10, batch_size=64)
Epoch 1/10
750/750 [==============================] - 7s 4ms/step - loss: 0.2209 - acc: 0.9348 - val_loss: 0.0719 - val_acc: 0.9797
Epoch 2/10
750/750 [==============================] - 3s 4ms/step - loss: 0.0650 - acc: 0.9799 - val_loss: 0.0659 - val_acc: 0.9811
Epoch 3/10
750/750 [==============================] - 3s 4ms/step - loss: 0.0458 - acc: 0.9856 - val_loss: 0.0437 - val_acc: 0.9866
Epoch 4/10
750/750 [==============================] - 3s 4ms/step - loss: 0.0350 - acc: 0.9890 - val_loss: 0.0452 - val_acc: 0.9870
Epoch 5/10
750/750 [==============================] - 3s 4ms/step - loss: 0.0286 - acc: 0.9907 - val_loss: 0.0413 - val_acc: 0.9883
Epoch 6/10
750/750 [==============================] - 3s 4ms/step - loss: 0.0232 - acc: 0.9926 - val_loss: 0.0410 - val_acc: 0.9878
Epoch 7/10
750/750 [==============================] - 3s 4ms/step - loss: 0.0203 - acc: 0.9934 - val_loss: 0.0420 - val_acc: 0.9886
Epoch 8/10
750/750 [==============================] - 3s 4ms/step - loss: 0.0166 - acc: 0.9948 - val_loss: 0.0398 - val_acc: 0.9879
Epoch 9/10
750/750 [==============================] - 3s 4ms/step - loss: 0.0118 - acc: 0.9964 - val_loss: 0.0464 - val_acc: 0.9877
Epoch 10/10
750/750 [==============================] - 3s 4ms/step - loss: 0.0120 - acc: 0.9959 - val_loss: 0.0478 - val_acc: 0.9888
Grad-CAM
여기서부터 Grad CAM 내용이다. Grad CAM은 CNN 모델의 가장 마지막 feature maps에 대해서 모델의 출력값을 미분하는 과정을 포함한다.
Feature maps이란
화가 난다. feature maps을 설명해야 한다. 그것도 아주 쉽게.
딥러닝은 흔히 여러층으로 구성되어 있다고 한다. 각 층에서 일어나는 것은 데이터 변환이다. 예를 들어, 우리의 데이터가 4차원 벡터 $(179, 70, 29, -7.5)^\top$라고 하자. 4차원 벡터가 딥러닝에 들어가서 첫 번째 은닉층 (hidden layer)를 지나면 더 좋은 벡터가 된다. 예를 들어, 4차원 벡터가 10차원 벡터 $(-1.44,\; 0.488, \;\cdots, \;0.29)^\top$. 이 10차원 벡터를 만드는 과정에 위에서 말한 학습가능한 파라미터가 있는 것이다. 좋은 파라미터는 좋은 10차원 벡터를 만들어낸다. 10차원 벡터는 층을 지나면 다른 벡터가 된다. 이렇게 더 좋은 벡터로 만들어주는 과정을 반복한다. 그리고 마지막 벡터의 원소들로 연산을 해줘서 마지막 예측 값을 내뱉게 된다. 이 모든 과장에 학습 가능한 파라미터가 있다. 손실 함수를 줄여주는 방향으로 파라미터가 점점 조정되면, 각 층에서는 점점 문제를 풀기 좋은 벡터를 만들어낼 수 있게 된다.
CNN은 위의 설명에서 벡터를 이미지로 바꿔주면 된다. CNN은 이미지를 입력 받는다. 예를 들어, $28 \times 28 \times 3$ 크기의 이미지를 입력 받는다. 합성곱층 (convolutional layer)를 하나 지나면 더 좋은 이미지로 바뀌게 된다. 예를 들어, $26 \times 26 \times 32$ 크기의 이미지가 된다. 사실, 이 친구에게 이미지라는 단어는 더 이상 사용할 수 없을 것이다. 대신 우리는 이 친구를 feature map이라고 부른다. 즉, feature map은 합성곱층을 지나면서 만들어진 더 좋은 이미지라고 이해하면 쉽다.
Grad CAM에서 모델의 마지막 feature maps을 사용한다는 것은 그냥 마지막 합성곱층을 지난 좋은 이미지로 이해하면 된다.
왜 미분하는데
화가 난다. 왜 미분을 해야하는지 설명을 해야 한다. 그것도 아주 쉽게.
미분이 무엇인가? $x$에서 함수 $f(x)$의 미분 값은 $x$가 아주 조금 변했을 때 $f(x)$가 얼마나 변하느냐를 나타내는 것이다.
그럼 마지막 feature maps으로 우리의 모델을 미분한다는 것은 무슨 의미인가? feature maps이 아주 조금 변했을 때, 우리의 모델이 얼마나 변하느냐를 나타낸다. 모델이 많이 변하고 조금 변하는 것이 무엇을 의미할까? 개와 고양이를 분류하는 예시를 생각해보자. 지금 우리의 모델이 충분히 훌륭해서 개는 개라고, 고양이는 고양이라고 잘 분류한다고 가정하자. 이때, 개 사진에서 얼굴을 고양이로 바꿔보자. 모델의 예측값은 개에서 고양이로 급변할 것이다. 반면, 사진의 배경을 맑은 날에서 흐린 날로 바꾼다고 해서 모델의 예측 값이 개에서 고양이로 바뀌진 않을 것이다. 이 예시가 무엇을 의미하는가? 사진에서 중요한 부분일 수록 조금만 변형을 가해도 모델의 예측값에 큰 변화를 준다. 마지막 feature maps에서 중요한 영역은 조금만 변해도 모델의 예측값이 크게 변하기 때문에 큰 미분값을 가질 것이고, 반대로 그다지 중요하지 않은 영역은 미분값이 작을 것이다.
Grad-CAM 구현
- 출처: https://keras.io/examples/vision/grad_cam/
- 주석 달아놓은 것 보든지 말든지.
def make_gradcam_heatmap(img_array, model, last_conv_layer_name, pred_index=None):
# 마지막 feature maps에 대한 모델의 미분을 계산하기 위해서
# 마지막 feature maps과 모델을 최종 예측값을 동시에 출력하는 모델을 새롭게 정의한다.
# 이것은 케라스 문법이기 때문에 익숙치 않을 수 있다.
# - Model 함수의 첫 번째 인자는 입력 객체, 두 번째 인자는 출력 객체이다.
# - 마지막 feature maps과 최종 예측값 두 개를 출력한다.
grad_model = tf.keras.models.Model(
[model.inputs], [model.get_layer(last_conv_layer_name).output, model.output]
)
# 이건 텐서플로우 문법이다.
# 모델에 이미지가 입력되고, 마지막 feature maps과 최종 예측값을 구하는 일련의 연산 과정을
# Computational graph라는 형태로 저장해놓는다. 이렇게 해야 미분값을 계산할 수 있다.
with tf.GradientTape() as tape:
last_conv_layer_output, preds = grad_model(img_array)
# 우리의 모델은 num_classes개의 예측값을 출력한다. 각 예측값은 데이터가 해당 클래스 확률값이다.
# 미분 (더 정확히는 그레디언트)는 한 개의 예측값에 대해서 계산할 수 있기 때문에
# 가장 확률값이 큰 예측값에 대응하는 클래스 (혹은 함수의 인자로 전달한 클래스)만을 고려할 것이다. -> class_channel
if pred_index is None:
pred_index = tf.argmax(preds[0])
class_channel = preds[:, pred_index]
# 이 친구가 바로 미분 계산이다.
# 모델의 어떤 한 클래스에 대한 예측값(class_channel) 을 마지막 feature maps(last_conv_layer_output)으로 미분한다.
grads = tape.gradient(class_channel, last_conv_layer_output)
# 마지막 feature maps은 여러 개의 채널을 갖고 있다. (현재 [1, 높이, 너비, 채널] 상태, 1은 데이터 개수)
# 각 채널마다 등장한 미분값들을 평균 내려주자. (채널의 중요도를 결정)
pooled_grads = tf.reduce_mean(grads, axis=(0, 1, 2))
# 우리는 마지막 feature maps에서 중요한 위치를 알고 싶다.
# 하지만 채널 개수가 많기 때문에 어떤 위치가 중요한지 결정해줘야 한다.
# 채널의 중요도를 가중치로 가중합을 해주자 ([높이, 너비, 1]가 됨)
last_conv_layer_output = last_conv_layer_output[0]
# @는 행렬곱 연산이다. 축을 잘 맞춰줌으로써 행렬곱이 곧 가중합 연산이 되도록 한 것이다.
heatmap = last_conv_layer_output @ pooled_grads[..., tf.newaxis]
heatmap = tf.squeeze(heatmap) # 축 쥐어짜서 (squeeze) 없애주기 ([높이, 너비, 1] -> [높이, 너비]가 됨)
# 0과 1사이 값으로 만들어주기
heatmap = tf.maximum(heatmap, 0) / tf.math.reduce_max(heatmap)
return heatmap.numpy()
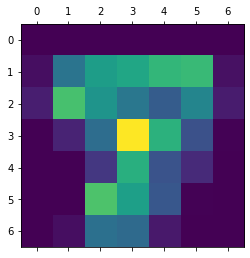
heatmap = make_gradcam_heatmap(X_test[0:1], model, 'max_pooling2d_1')
plt.matshow(heatmap)
plt.show()
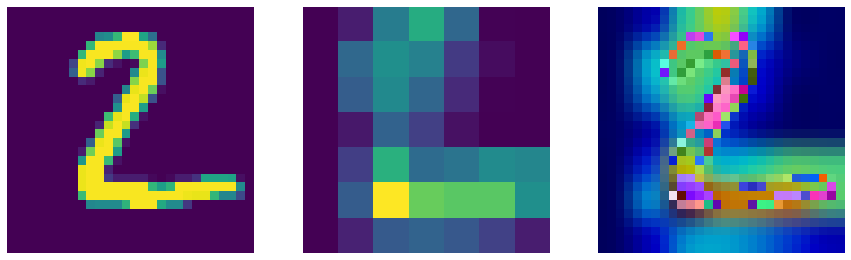
def display_gradcam_with_img(img, heatmap, alpha=0.4):
# 0과 1 사이의 값을 갖는 행렬 -> 0과 255 사이의 정수를 갖는 행렬
heatmap = np.uint8(255 * heatmap)
# 이쁜 히트맵을 위한 칼라맵 설정
jet = cm.get_cmap("jet")
jet_colors = jet(np.arange(256))[:, :3] # 0~255에 대응하는 RGB 값 불러오기 [256, 3]
jet_heatmap = jet_colors[heatmap] # RGB 이미지가 됨 (왜 그렇게 되는지는 굉장히 어려워 보임 ...)
jet_heatmap = keras.preprocessing.image.array_to_img(jet_heatmap) # 행렬을 이미지로 바꿔주기 (이미지 크기 바꾸기 위해)
jet_heatmap = jet_heatmap.resize((img.shape[1], img.shape[0])) # 히트맵 사이즈를 이미지 크기로 바꿔주기
jet_heatmap = keras.preprocessing.image.img_to_array(jet_heatmap) # 이미지를 행렬로 바꿔주기
superimposed_img = jet_heatmap * alpha + img # 히트맵과 이미지 겹치기 (덧셈 연산으로 가능)
superimposed_img = np.uint8(superimposed_img)
# 그림 그려
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
axes[0].imshow(img) # 원본 이미지 그려
axes[1].imshow(heatmap) # 히트맵 그려
axes[2].imshow(superimposed_img) # 겹친 이미지 그려
for ax in axes:
ax.axis('off') # 축에 눈금이랑 숫자 다 없애
img = X_test[1]
heatmap = make_gradcam_heatmap(img[np.newaxis], model, 'max_pooling2d_1')
k = display_gradcam_with_img(255 * img, heatmap, alpha=0.8)