
코로나 확진자 동향 데이터 수집 및 시각화
학교에서나 개인적으로 프로젝트를 하고자 할 때, 요새 가장 인기 있는 주제는 코로나19일 것이다. 최근 학생들을 대상으로 네이버에 코로나를 검색했을 때 나오는 일별 신규 확진자 수 그래프를 비슷하게 그려보는 튜토리얼을 준비했었다. 최근 가장 주목 받고 있는 주제인만큼 정형화된 데이터를 찾을 수 있을줄 알았는데 공공데이터포털에서 OpenAPI 형태로 제공하고 있었다. 크게 복잡한 과정이 없다고는 하지만 OpenAPI가 처음인 분들은 진입하기 어려울 것이다. OpenAPI 공포증이 있는 사람들을 위해 이 글을 작성해본다.
이 포스트에서 다룰 내용들
공공데이터포털에서 OpenAPI 신청하기
공공데이터포털에서 보건복지부_코로나19 감염_현황 OpenAPI를 신청하는 방법을 알아보자. 먼저, 공공데이터포털에 접속하여 로그인까지 하자.
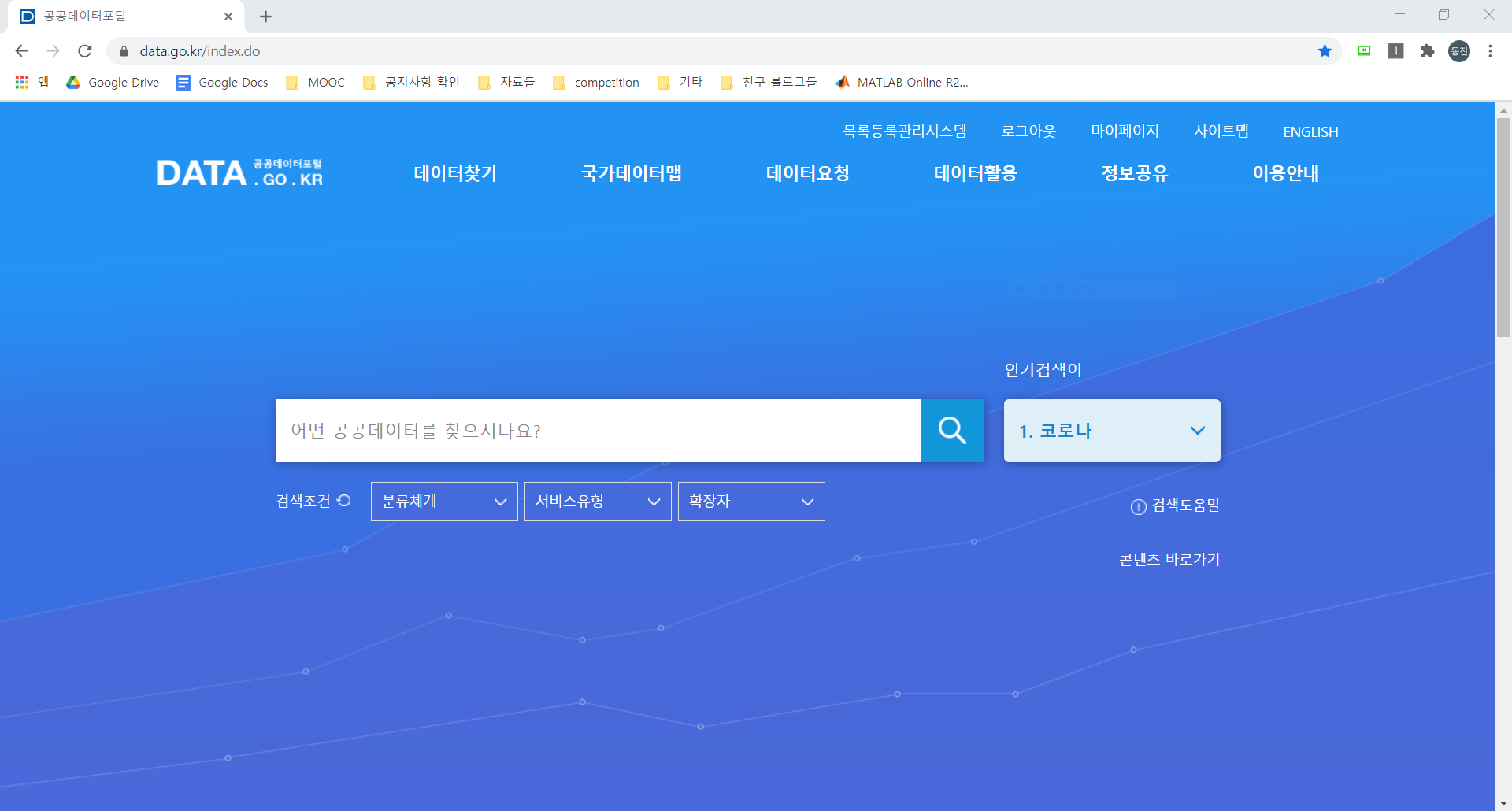
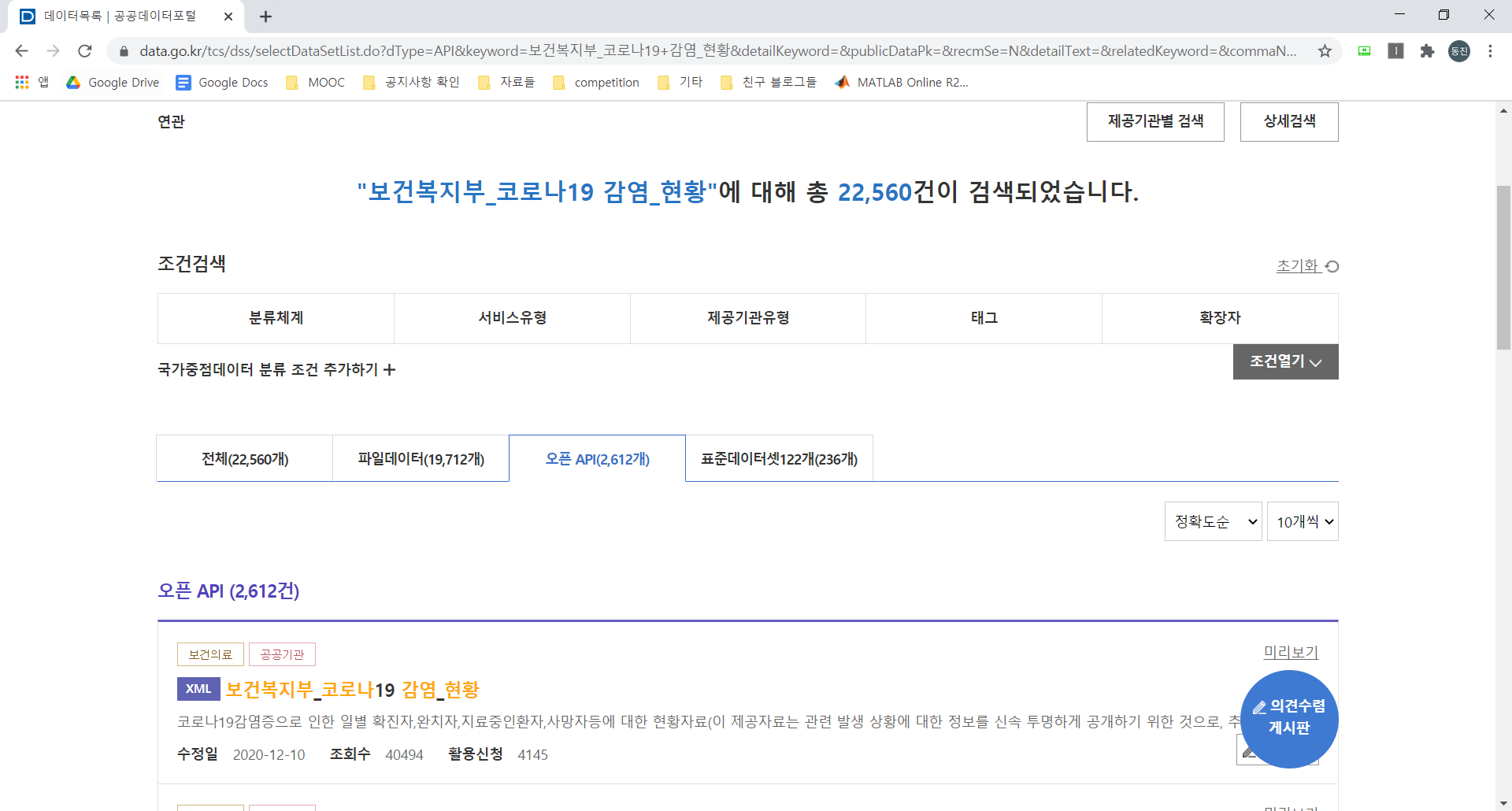
다음으로 보건복지부_코로나19 감염_현황 을 검색하고, 결과창에서 오픈 API 로 들어가서 보건복지부_코로나19 감염_현황 을 클릭하자
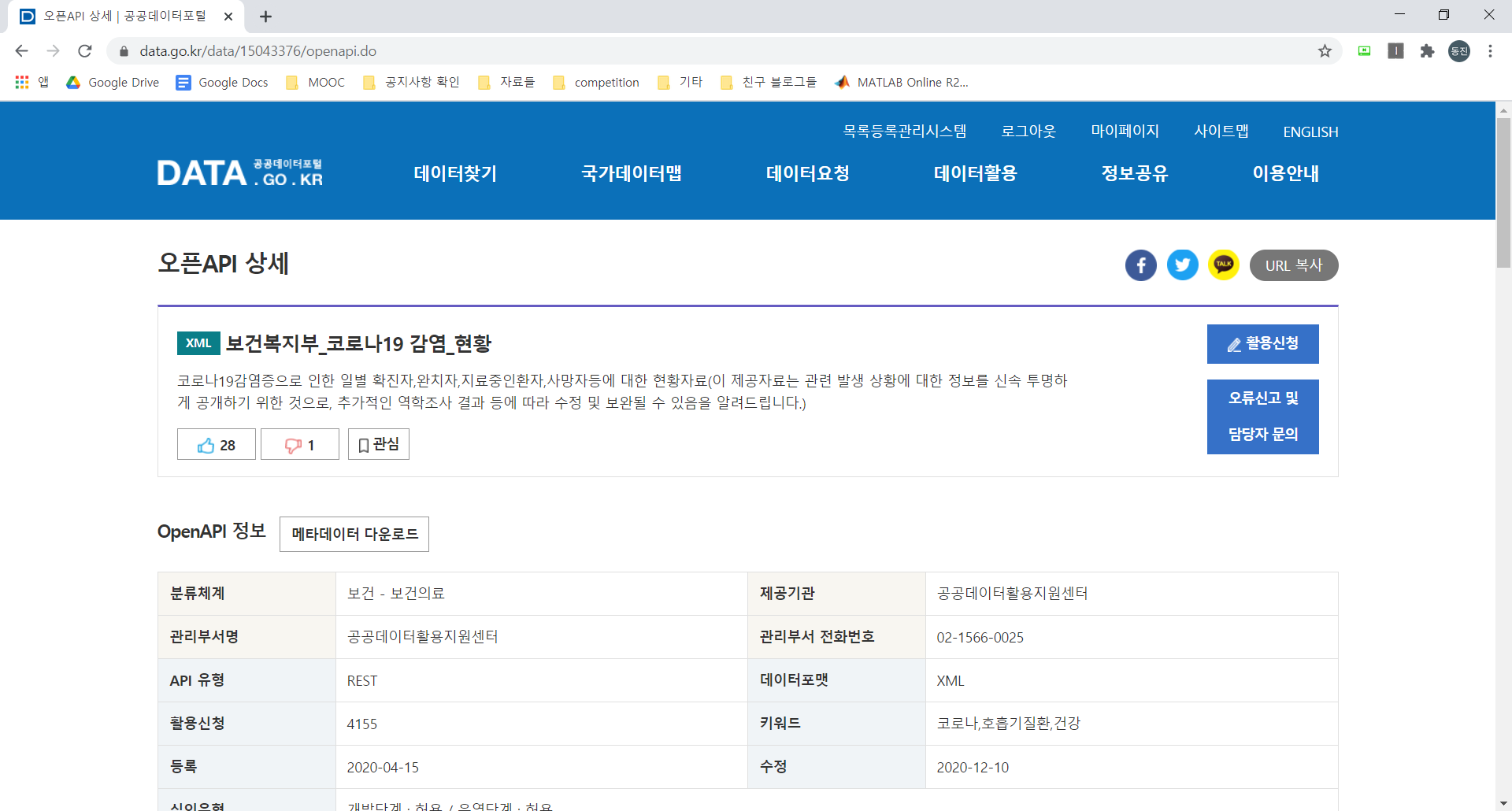
오른쪽에 활용신청 버튼을 누르자
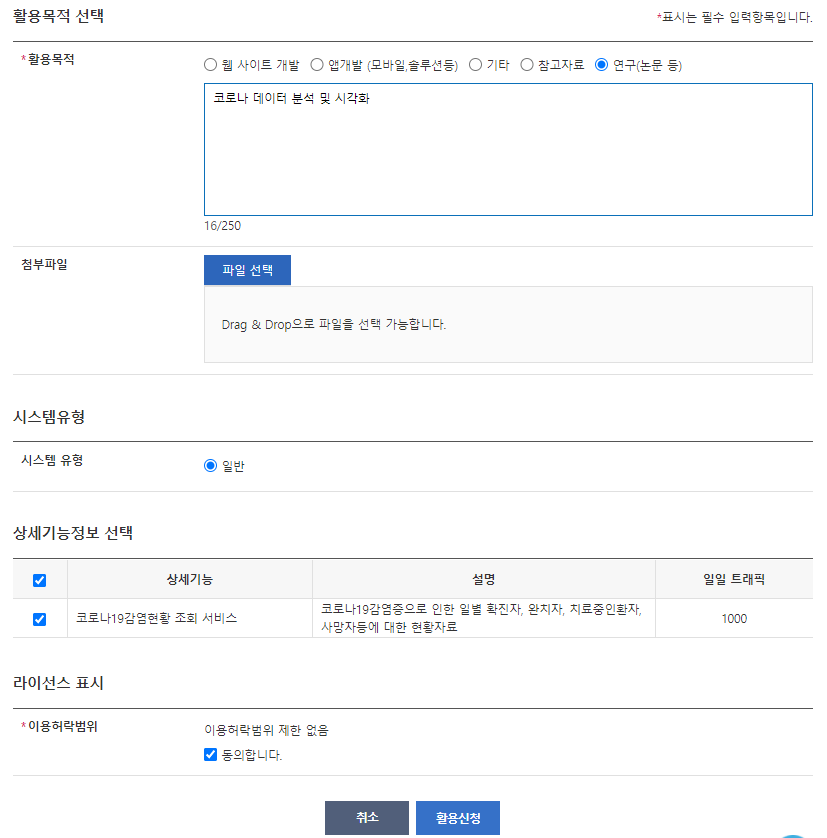
활용목적을 그럴싸하게 적어주고 라이선스 표시에 “동의합니다.” 를 체크하고 활용신청을 눌러주자. 해당 OpenAPI는 자동 승인이기 때문에 활용목적을 어떻게 적을까 오래 고민하지 않아도 된다.
활용신청을 누르면 승인이 되었다는 메세지와 함께 1-2시간 후에 정상적인 사용이 가능하다고 안내가 나온다. 짧으면 1-2시간, 길면 며칠 후에 이용가능하다. 내가 지금 현재 OpenAPI를 사용할 수 있는지 알 수 있는 방법은
마이페이지→[승인] 보건복지부_코로나19 감염_현황→ 활용신청 상세기능정보의 미리보기확인→미리보기
을 실행했을 때 “SERVICE_KEY_IS_NOT_REGISTERED_ERROR” 가 나오지 않고 “NORMAL SERVICE” 가 나오면 된다. 만약 며칠이지나도 안 된다면 OpenAPI 상세설명에 들어가서 오류신고 및 담당자 문의으로 문의를 하자.
OpenAPI에 데이터 요청하고 처리하기
이제 파이썬에서 OpenAPI에 데이터를 요청하고 처리하는 방법을 알아보자. 우리가 API에 데이터를 요청하면 순순히 *.csv 이나 *.xlsx 등의 정형화된 파일을 주지 않는다. 대신, 많은 사람들이 다양하게 개발할 수 있는 일반적인 형태로 반환해준다. 이번 장에서는 파이썬 내장 라이브러리인 urllib을 사용하여 API에 데이터를 요청하고, 받은 응답을 BeautifulSoup4를 통해 처리해볼 것이다. BeautifulSoup4는 다음 명령어를 통해 설치할 수 있다.
! pip install beautifulsoup4
먼저 필요한 라이브러리들을 임포트해주자. 사용하고 있는 파이썬 버전에 따라 urllib에 있는 함수들이 각자 다른 곳에 숨어있을 때가 있다. 이 때는 구글링을 이용해서 알잘딱깔센 (역주: 알아서 잘 딱 깔끔하게 센스있게) 해주자. 참고로 필자는 파이썬 3.8을 사용했다.
import pandas as pd
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
from urllib.request import Request, urlopen
from urllib.parse import unquote, quote_plus, urlencode
앞으로 우리가 하게 될 과정을 쉽게 말하자면,
- 어떤 주소를 가진 웹사이트에 들어감으로써 데이터를 요청하게 되고,
- 요청에 대한 답변을 웹사이트에 표시해준다.
가장 먼저 우리가 데이터를 요청할 때 필요한 인자들을 정의하자. servicekey에는 각자
마이페이지→[승인] 보건복지부_코로나19 감염_현황→ 서비스 정보의일반 인증키 (UTF-8)
를 복사해서 넣자. 잠시 후에 url에 여러 인자들을 추가로 적어줄 것인데, 그 때 사용하는 urlencode 함수에 의해 우리의 일반 인증키가 다른 값으로 적혀진다. 따라서, servicekey를 decode해준 decodekey도 정의해놓는다.
url = 'http://openapi.data.go.kr/openapi/service/rest/Covid19/getCovid19InfStateJson'
servicekey = '{일반 인증키 (UTF8)}'
decodekey = unquote(servicekey)
다음으로 데이터 요청에 필요한 인자들을 url 뒤쪽에 쭈욱 적어주자. ? 인자들이 시작함을 알려준다. 인자들은 다음과 같다.
serviceKey: 일반 인증키startCreateDt: 시작일, 예) 20210105endCreateDt: 종료일, 예) 20210115
예시 인자들을 넘겨줄 경우, 2021년 01월 05일부터 2021년 01월 15일까지 데이터가 해당 주소의 웹사이트에 표시된다.
- 숙제: 아래
URL에 저장된 주소를 인터넷 브라우저 주소창에 입력하여 들어가보시오.
startCreateDt = 20210105
endCreateDt = 20210115
query_params = '?' + urlencode({
quote_plus('serviceKey'): decodekey,
quote_plus('startCreateDt'): startCreateDt,
quote_plus('endCreateDt'): endCreateDt
})
URL = url + query_params
크롬 브라우저에서 URL 주소로 들어가면 다음과 같이 나타난다. 만약, <header> 태그에 있는 <resultMsg> 태그 값이 NORMAL SERVICE.이 아니라면 어딘가 잘못된 것이다. 코드를 다시 한 번 확인해보거나 구글링을 해서 디버깅하자.
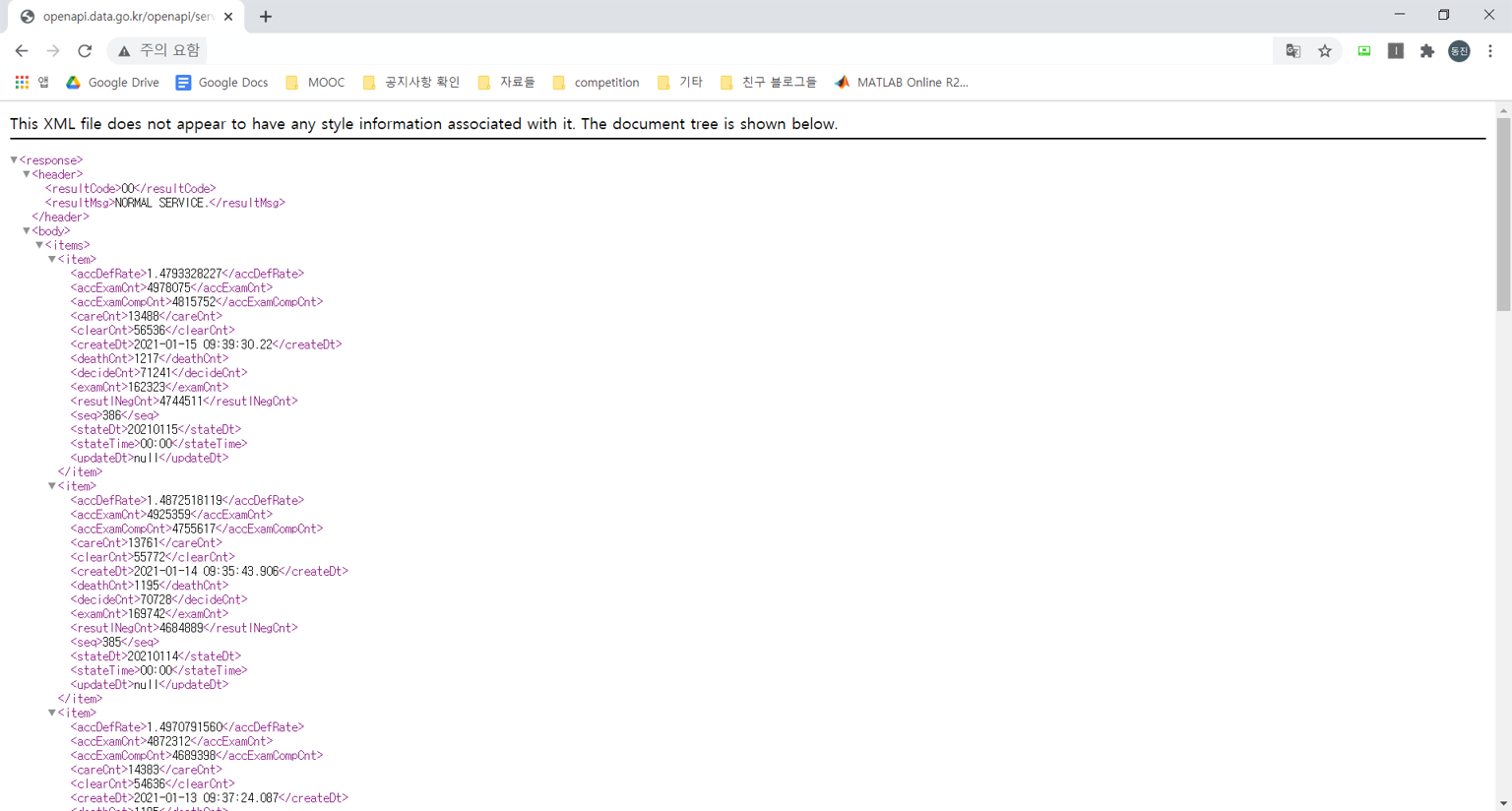
우리는 위와 같은 형태의 데이터를 원했던 것이 아니다. *.csv 나 *.xlsx 처럼 정형화된 데이터가 필요할 것이다. 하지만 결과 사이트를 보면 분명 규칙성이 존재한다. <body> 태그 - <items> 태그 안에 일자별 데이터들이 <item> 태그로 구분되어 있다. 그리고 각 <item> 태그 안에 있는 <decideCnt>가 누적 확진자 수다. 이 값들만 선택해서 얻고 싶다. BeautifulSoup4를 사용하면 태그들의 규칙성을 파악하여 원하는 태그들에 접근할 수 있다. 먼저, 파이썬에서 URL에 접속하고 사이트에 표시되는 html 을 가져와보자.
- (숙제)
page변수에 어떤 값이 저장되어 있는지 출력해보시오.
request = Request(URL)
page = urlopen(request).read()
다음 단계는 BeautifulSoup4 를 사용하고, 그 대단함에 감탄할 시간이다.
- (숙제)
parse변수에 어떤 값이 저장되어 있는지 출력해보시오. - (숙제)
pd.Series.diff메서드가 뭐하는 친구인지 공부해보시오.
soup = BeautifulSoup(page, 'html.parser')
parse = soup.find_all(['decidecnt', 'statedt']) # decidecnt 태그와 statedt 태그 다 찾기
df = []
for dt, cnt in zip(parse[1::2], parse[0::2]):
df.append([dt.text, int(cnt.text)]) # 태그 안의 값은 ".text"를 통해 접근할 수 있음
df = pd.DataFrame(df, columns=['날짜', '누적확진자'])
df = df.sort_values(by='날짜').reset_index(drop=True)
df['일별확진자'] = df['누적확진자'].diff()
df = df.loc[1:].reset_index(drop=True) # 맨 앞의 데이터는 지우기 (일별 확진자가 계산되지 않았기 때문에)
df['일별확진자'] = df['일별확진자'].astype(int)
df
| 날짜 | 누적확진자 | 일별확진자 | |
|---|---|---|---|
| 0 | 20210106 | 65816 | 838 |
| 1 | 20210107 | 66684 | 868 |
| 2 | 20210108 | 67358 | 674 |
| 3 | 20210109 | 67999 | 641 |
| 4 | 20210110 | 68663 | 664 |
| 5 | 20210111 | 69114 | 451 |
| 6 | 20210112 | 69650 | 536 |
| 7 | 20210113 | 70204 | 554 |
| 8 | 20210114 | 70728 | 524 |
| 9 | 20210115 | 71241 | 513 |
네이버 검색 결과처럼 시각화하기
BeautifulSoup4를 이용하여 html 으로부터 원하는 정보만 가져오는데 성공했고, 이를 바탕으로 데이터를 만들어보았다. 이제 네이버에 코로나를 검색하였을 때 나오는 일별 신규 확진자 수 그래프랑 비슷하게 시각화를 해보자. 먼저, 그냥 marplotlib의 bar 함수를 사용해보자.
fig, ax = plt.subplots(1, 1, figsize=(12, 6))
ax.bar(x=df['날짜'].astype(str), height=df['일별확진자'])
plt.show()
네이버와 비교했을 때 막대의 너비가 너무 넓고 색상도 다르다. 이를 조정해보자.
fig, ax = plt.subplots(1, 1, figsize=(12, 6))
ax.bar(x=df['날짜'].astype(str), height=df['일별확진자'], width=0.1, color='#FFE3E3')
plt.show()
둘리에서 나오는 뼈만 앙상하게 생선같은 느낌이다. 눈금을 추가하여 허전한 공간들을 채워넣어 주자. 그리고 spines 를 이용하여 그래프의 테두리를 설정해주자
fig, ax = plt.subplots(1, 1, figsize=(12, 6))
ax.bar(x=df['날짜'].astype(str), height=df['일별확진자'], width=0.1, color='#FFE3E3')
# Remove side edges
ax.spines['left'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['top'].set_color('gray')
ax.spines['bottom'].set_color('gray')
plt.grid(axis='y', color='gray')
plt.show()
다음으로 빈도수를 각 막대그래프 위에 표시해주자. s=f'{freq:,}' 에 “,” 은 숫자의 천 단위마다 쉼표를 추가해준다.
fig, ax = plt.subplots(1, 1, figsize=(12, 6))
ax.bar(x=df['날짜'].astype(str), height=df['일별확진자'], width=0.1, color='#FFE3E3')
# Annotate frequncies
for i, freq in enumerate(df['일별확진자'].values):
if len(str(freq)) == 3:
x = i - 0.18
else:
x = i - 0.3
plt.text(x=x, y=freq+40, s=f'{freq:,}', fontdict={'fontsize':12, 'color':'gray', 'fontweight': 'bold'})
# Remove side edges
ax.spines['left'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['top'].set_color('gray')
ax.spines['bottom'].set_color('gray')
plt.grid(axis='y', color='gray')
plt.show()
마지막으로 축들을 설정해주자. 날짜를 20210106와 같은 형태에서 1.6 같은 형태로 바꿔주는 파트가 마음에 들지는 않지만 결과만 좋으면 되는 것이다.
fig, ax = plt.subplots(1, 1, figsize=(12, 6))
ax.bar(x=df['날짜'].astype(str), height=df['일별확진자'], width=0.1, color='#FFE3E3')
# Annotate frequncies
for i, freq in enumerate(df['일별확진자'].values):
if len(str(freq)) == 3:
x = i - 0.18
else:
x = i - 0.3
plt.text(x=x, y=freq+40, s=f'{freq:,}', fontdict={'fontsize':12, 'color':'gray', 'fontweight': 'bold'})
# Remove side edges
ax.spines['left'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['top'].set_color('gray')
ax.spines['bottom'].set_color('gray')
xticks = df['날짜'].apply(lambda x: str(int(str(x)[4:6])) + '.' + str(int(str(x)[6:8])))
plt.xticks(df['날짜'].astype(str), xticks, fontsize=12)
plt.yticks(fontsize=12)
plt.ylim(0, 1200)
plt.grid(axis='y', color='gray')
plt.show()
이상으로 이번 글을 마치도록 하겠다. 찡긋.
