
데드 바이 데이라이트 스킬 체크
2023-06-18 »
Skill Check 환경 및 DQN 에이전트
- 제목: Skill Check 환경 및 DQN 에이전트
- 기간: 1주일
- 링크: https://github.com/HiddenBeginner/skill_check_env
- 프로젝트 설명: 게임 Dead by Daylight의 quick time event (QTE) 요소 중 하나인 스킬 체크를 모방하여 환경을 만들고 DQN 에이전트로 환경 해결
환경 설명
Dead by Daylight에서 생존자가 발전기 수리나 회복 등을 수행할 때 낮은 확률로 quick time event인 스킬 체크가 발동한다. 생존자가 스킬 체크를 성공하면 진척도 보너스를 받지만, 만약 실패하면 진척도 감소 뿐만 아니라 살인마에게 알림이 가게 되기 때문에 생존하기 위해서는 반드시 성공해야 하는 요소이다.
스킬 체크 발동시 생존자 화면 가운데에 12시 방향에 빨간 바늘이 놓여져 있는 원이 하나 생긴다. 빨간 바늘은 약 1.0초 동안 시계 방향으로 360도를 빠르게 회전하며, 생존자는 원 위의 임의의 위치에 생긴 성공 구간에 빨간 바늘이 들어오면 스페이스바를 눌러 스킬 체크를 해야 한다. 성공 구간의 길이는 약 55도이며, 그 중 첫 10도에서 스킬 체크를 성공하면 스킬 체크 대성공으로 간주되어 진척도 보너스를 받게 된다. 나머지 45도 안에서 스킬 체크를 성공하면 일반 성공으로 간주되며 진척도 보너스는 없다. 만약, 성공 구간 이전에 스킬 체크를 하거나, 성공 구간을 지날 때까지 스킬 체크를 하지 못하게 되면 스킬 체크 실패로 간주되며 진척도 패널티를 받게 된다.
이에 영감을 받아 Skill Check 환경을 만들게 되었다. 한 에피소드를 한 번의 스킬 체크 상황으로 간주했다. 매 에피소드마다 길이 55도의 성공 구간이 90도 ~ 360도 사이에서 임의로 생성되며, 성공 구간의 첫 10도를 대성공 구간, 나머지 45도를 일반 성공 구간으로 구분하였다. 에피소드 시작시 빨간 바늘이 12시 방향을 가리키고 있으며, 120 FPS을 가정하여 360도 회전을 120 프레임으로 나누었으며 따라서 1 프레임이 지날 때마다 빨간 바늘이 3도씩 움직이게 된다.
Observation space는 $\mathcal{S} \subseteq \mathbb{R}^{84 \times 84 \times 1}$이며, 현재 프레임의 이미지를 observation으로 받게 된다. Atari 환경 등에서는 Markov property를 만족시키기 위하여 과거 $t$개의 프레임을 합쳐서 observation을 사용하지만, 이 환경의 경우 바늘의 회전 속도가 항상 동일하기 때문에 1장의 프레임만으로도 Markov property를 만족하게 되기 때문에 stacked 프레임을 사용하지 않았다. Action space는 $\mathcal{A}= { 0, 1}$이며, 0은 아무 행동을 하지 않으며, 1은 스킬 체크를 하는 행동이다.
0의 행동을 하면 0의 보상을 받으며 바늘이 3도 회전하게 된다. 바늘이 대성공 구간에 위치했을 때 1의 행동을 하면, +10.0 보상을 받으며 에피소드가 종료된다. 성공 구간에 위치했을 때 1의 행동을 할경우 +1.0 보상을 받으며 에피소드가 종료된다.
성공 구간 이전에 1의 행동을 하면 -5.0의 보상을 받으며 에피소드가 종료된다. 다음 상태에서 바늘이 성공 구간을 넘어서면 -5.0의 보상을 받으며 에피소드가 종료된다.
DQN 에이전트
위에서 만든 Skill Check 환경에 DQN 알고리즘을 직접 구현하여 적용해보았다. 처음에는 DQN 논문에 있는 네트워크 구조와 하이퍼파라미터를 그대로 따라서 실험을 했다. 환경이 쉬운 환경임에도 에이전트는 학습이 종료될 때까지 내내 -5.0 보상만 받았다.
학습 실패 원인 분석
생각해볼 수 있는 원인 한 가지는 다음과 같다. 에이전트가 양수 보상 신호를 받기 위해서는 바늘이 성공 구간에 도달하기 전까지 반드시 0 행동을 해야 한다. 이를 프레임으로 환산해보면 최소 30 프레임까지는 0의 행동을 해야만 한다는 것이다. 완전 랜덤 행동을 하는 에이전트의 경우, 30 프레임 동안 0의 행동만 취할 확률은 $\frac{1}{2^{30}}$이 된다. 따라서 학습 초기에 완전 랜덤 탐색 동안에는 양수 보상을 받을 확률이 굉장히 낮다. 하지만 다행히도 성공 구간 이전에 1의 행동을 할 경우 -5.0 보상을 받기 때문에, 에이전트는 성공 구간 이전에는 0의 행동을 하는 것이 더 좋다는 것을 학습하고 0의 행동만 수행하게 된다.
하지만 에이전트가 성공 구간 이전에 항상 0의 행동을 수행한다고 해도 $\epsilon$의 확률로 랜덤 탐색을 수행하며 여기서 1의 확률을 취할 확률이 $\frac{1}{2}$이다. 즉, $\frac{\epsilon}{2}$의 확률로 1의 행동이 수행된다. 기존 DQN 논문에서는 $\epsilon=1$에서 시작하여 이후 1백만 steps 동안 $\epsilon=0.1$로 선형적으로 감소시킨다. $\epsilon=0.1$이라고 할 때 1의 행동을 취할 확률은 $0.05$가 된다. 30 프레임 동안 1의 행동을 한번이라도 할 확률은 1 빼기 30 프레임 동안 모두 0의 행동을 취할 확률이며, 이는 $1 - (0.95)^{30}=0.78$이다. 따라서 기존의 $\epsilon$ 관련 하이퍼파라미터로는 성공 구간에 도달하기 조차 힘들다는 것을 확인했다.
문제 해결 결과
문제 분석을 바탕으로, 초기 $\epsilon=0.1$로 설정하고 이후 1백만 steps 동안 $\epsilon=0.005$로 선형적으로 감소시키게 수정했더니 에이전트가 성공적으로 환경을 해결하는 것을 확인할 수 있었다. 환경과 상호작용 횟수에 따른 에이전트의 Return 곡선은 다음과 같다.
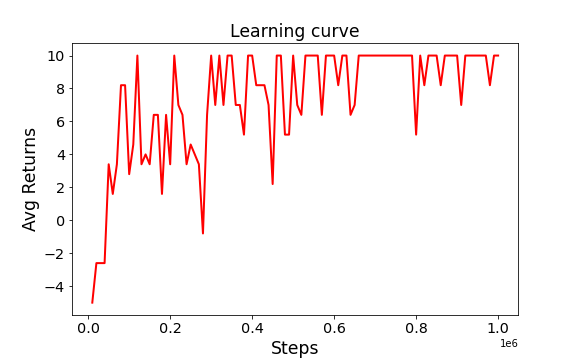
학습이 종료된 후 10번의 에피소드에 대해서 테스트했을 때, 1번만 일반 성공을 한 것을 제외하고 9번은 대성공을 하였다. 애니메이션은 아래와 같다. 회전 속도가 많이 느려보이는데, 환경을 120 FPS로 만들다보니 프레임 수가 많아져서 그렇다.

이 외에도 스킬 체크 실패한 케이스를 찾기 위해서 역체리피킹을 하였다. 아래 애니메이션는 5번의 에피소드에 대해서 테스트하였고, 두 번째 에피소드에서 스킬체크 실패를 했다. 스킬 체크 실패의 원인을 찾기 위하여 각 상태에서의 Q-network의 출력값도 시각화해서 살펴보았다. 0의 행동과 1의 행동 중 Q값이 더 큰 쪽을 파란색으로 나타냈다.
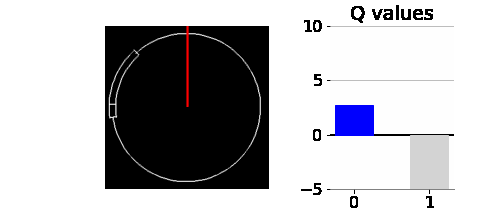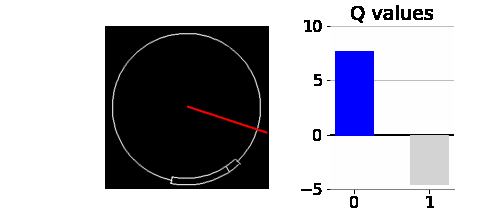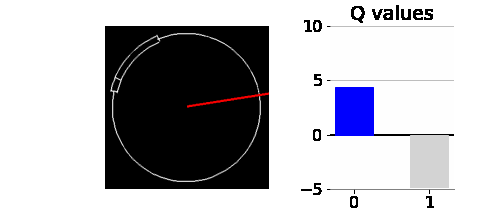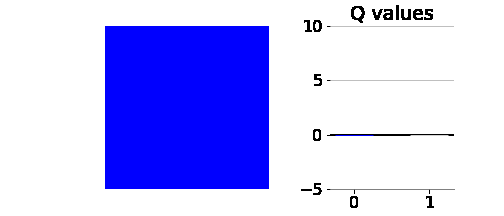
일반적으로 바늘이 스킬 체크 성공 구간에 가까워질수록 0의 행동에 대한 Q값이 증가한다. 그 동안 1의 행동에 대한 Q값은 -5이다. 그리고, 성공 구간 바로 직전부터 1의 행동에 대한 Q값이 크게 증가하여 0의 행동에 대한 Q값을 역전하면서 1의 행동을 취하게 된다. 하지만, 두 번째 에피소드에서는 대성공 구간 동안 0과 1의 행동에 대한 Q값이 모두 10에 가까운 값이며, 1의 Q값이 0의 Q값을 근소한 차이로 역전하지 못하여 0의 행동을 취한다. 대성공 구간을 지나면 일반 성공 구간인데, 여기서 스킬 체크를 성공하면 +1을 보상을 받는다. 하지만 Q network가 이를 학습하지 못했는지 행동 가치를 0으로 예측하고 있다. 이 때문에 성공 구간에서도 1의 행동을 취하지 못하고 결국 스킬 체크에 실패하게 된 것으로 보인다.
